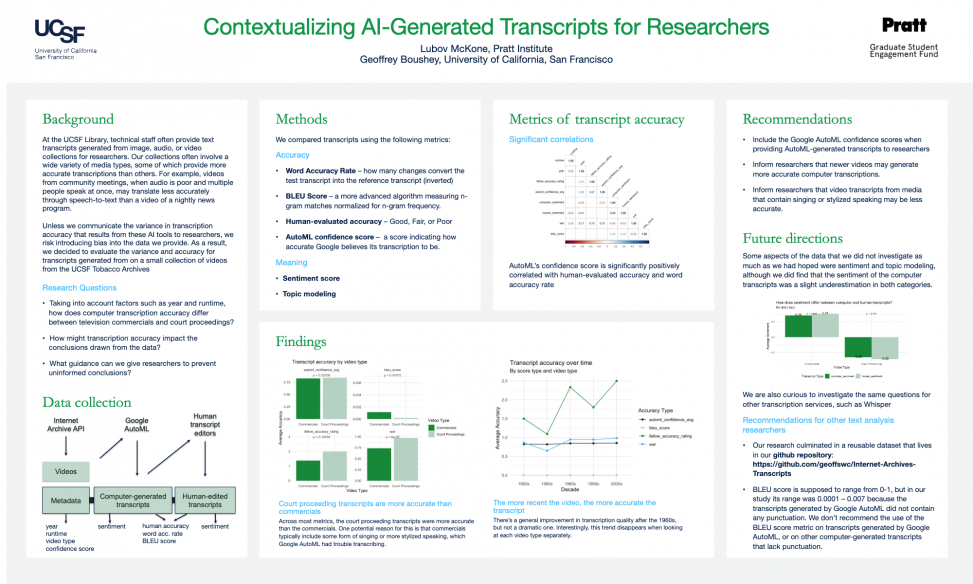
This past summer, I completed a Data Science Fellowship at the UCSFS’s Industry Documents Library. The UCSF Industry Documents Library is a vast collection of resources encompassing documents, images, videos, and recordings. These materials can be studied individually, but increasingly, researchers are interested in examining trends across whole collections, or subsets of it. In this way, the Industry Documents Library is also a trove of data that can be used to uncover trends and patterns in the history of industries impacting public health. In this project, the Industry Documents Library wanted to investigate what information is lost or changed when its collections are transformed into data.
There are many ways to generate data from digital collections. In this project we focused on a combination of collections metadata and computer-generated transcripts of video files. Like all information, data is not objective but constructed. Metadata is usually entered manually and is subject to human error. Video transcripts generated by computer programs are never 100% accurate. If accuracy varies based on factors such as the age of the video or the type of event being recorded, how might this impact conclusions drawn by researchers who are treating all video transcriptions as equally accurate? What guidance can the library provide to prevent researchers from drawing inaccurate conclusions from computer-generated text?
The final poster produced for this project can be accessed here.