The Twitter portion of this project covers two datasets, one of which is primarily a subset of the other with partial overlap. We collected one set of tweets from November 8, 2016 – March 5, 2017 that contain the phrase “fake news”, and one subset of tweets from the same time period that also contain the hashtag “#fakenews”. To collect this data, we used open source Python code that returned nine fields of data for each tweet:
- username
- timestamp
- number of retweets
- number of favorites
- tweet text
- mentions within the tweet
- hashtags within the tweet
- tweet ID
- permalink
We ran the code for each day in our time period twice, once for “fake news” and once for “#fakenews”. We then saved the data from each day as its own text file (separated into “#fakenews” files and “fake news” files). It should be mentioned that on account of the script parsing, retweets were not collected. Barring the overlap of “fake news” tweets that happened to include “#fakenews”, each tweet would be collected only once rather than accrue copies. An absence of data for any field was still recorded in the CSV output, indicating 0 for quantitative fields like retweets and favorites and an empty space between delimiters for the text fields.
Using Terminal’s cat function, we combined the text files for each day into a single file for each search. In R, we split these files based on a delimiter provided by the collection code and subsetted the data into separate files for usernames, hashtags, mentions, and tweet text. For each of these subsets, we retained the ID, timestamp, number of retweets, and number of favorites for each tweet. In the case of hashtags and usernames, each occurrence of a hashtag/mention within a tweet was given a separate row, with the ID, timestamp, number of retweets, and number of favorites filled down for multiple occurrences of hashtags/mentions within tweets. Term frequency data per day was calculated from the tweet text using R (stopwords were removed and terms were stemmed).
We collected about 4.6 million tweets that contained the phrase “fake news” and 1.3 million tweets which contained the hashtag “#fakenews”. Further analysis revealed that most of the “#fakenews” tweets also contained the phrase “fake news”, yielding 3.3 million unique “fake news” tweets and 2000 unique “#fakenews” tweets. We ultimately analyzed each corpus based on the initial collection values (4.6m and 1.3m) so as to analyze the implications of the subset.
The Twitter datasets were analyzed using Tableau Public.
Methods For Twitter Analysis
In broad strokes, the vernacular of Twitter —such as “mentions”, “hashtags”, and “retweets”—suggests a variety of critical understandings for how a single phrase might be utilized by users. Given the breadth of tweet metadata we collected, we aimed to analyze both “fake news” and “#fakenews” discourse from several angles. The following methods for Twitter analysis reflect the key dimensions of our Twitter analysis.
Hashtags (terms):
For both the “fake news” and “#fakenews” datasets, we were interested in the frequency of particular hashtag usage over time. The scale of our tweet collection precluded in-depth textual analysis for terms directly surrounding these hashtags, such as clarifying when “#trump” might be used as a partisan qualifier of fake news in either direction. Instead, our collection methods mean that instances of “#trump” and other such hashtags have been visualized as an indicator of a hashtag’s cumulative activity on a particular day.

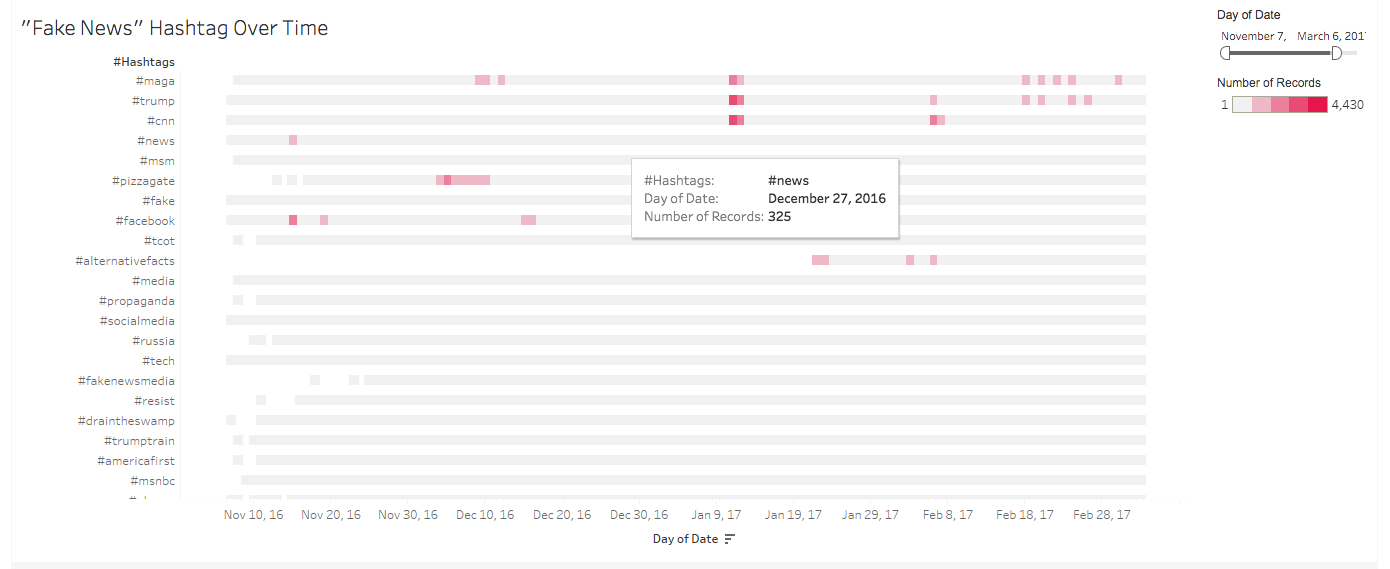
“Fake News” – Hashtags Over Time
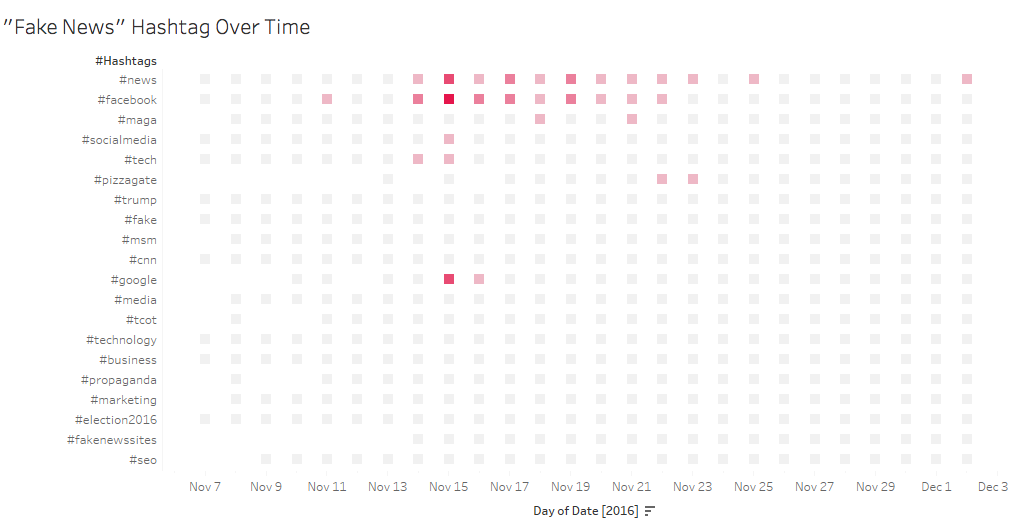
“#Fakenews” – Hashtags Over Time
With the hashtag data, we determined that the actual hashtags fell into two broad types: hashtags concerning people, institutions, and general topics (i.e. “#trump”, “#facebook”, “#news” respectively); and hashtags which appeared as complete and often ideological phrases (i.e. “#maga”, “#resist”, “#draintheswamp”). In an effort to cut across the dissimilarity between Twitter vernacular and the traditional news sources’ metadata terms, our analysis classifies the former kind of hashtag as established topics, more akin to direct mentions as is discussed below. The second type of hashtag, then, can be differentiated as terms. By differentiating these phrasal hashtags as terms, we hope to illuminate how the innovation of the hashtag has seemingly generated representations of fake news discourse which are largely idiomatic to this new media. While traditional news discourse may discuss the political underpinnings of these terms and in some cases recite them, their syntactical rendering on Twitter means that they cannot be considered analogous to newspaper “topics”.
One key approach to analyzing the hashtag data was to use hashtags to direct our research about historical events addressed by fake news discourse. For instance, spikes in usage of “#facebook” over a few particular days in Period 1, or “#pizzagate” in the days following reports of a gunman appearing at a pizzeria allegedly scandalized by Hillary Clinton, suggest that Twitter users use hashtags to respond to and disseminate breaking stories in near-real time. While it is likely that textual analysis of these thousands of tweets would simply confirm Twitter’s reputation as a quickly responsive media outlet, the fact that users identify and utilize controlled hashtags within a greater stream of hashtagged activity suggests something not only about how users talk, but about how users talk together. Early periods exhibit a small set of hashtags being used frequently (#news, #cnn, #facebook), while later periods see more concentrated hashtags such as #alternativefacts and #muslimban coexist as extensions of the fake news umbrella term. In broad strokes, this project understands the frequency of hashtags as a reflection of the diffusion of fake news discussion over time.
Mentions (topics):
A comparison of hashtag frequency across time and mention frequency across time reveals many of the same terms rising to the top within both the “fake news” corpus and the “#fakenews” corpus. In many cases, the hashtag and mention frequencies occur synchronously: @cnn/#cnn (period 3), #realdonaldtrump/#trump (periods 3,4,5), #news/ten news outlets among the 20 most frequently mentioned accounts. In one sense, non-idiomatic hashtags such as these might be considered “topics” by the logic of why we have classified mentions as topical: they refer to extant subjects and entities by which public knowledge may anchor discussion around. All of the top mentioned accounts within each dataset fall into one of three categories that are subject to some degree of public knowledge: media, people, or people associated with media.
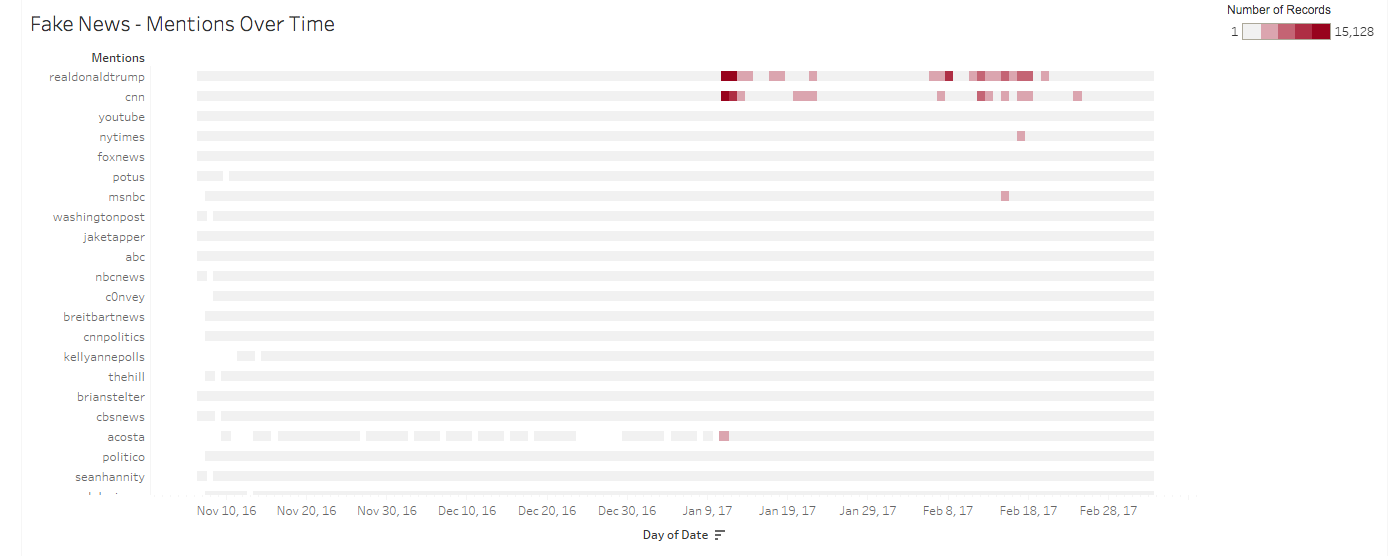
Fake News – Mentions Over Time

#Fakenews – Mentions Over Time
Given the preceding analysis of hashtags as a method of users talking together, however, direct mentions are distinguished by their unilateral function within Twitter conversation. In these examples where hashtags and mentions may align, this distinction of multilateral/unilateral presents a critical framework for documenting how users make variable use of different functions of Twitter vernacular. If someone writes “#cnn”, they are knowingly submitting their media record into an open and searchable stream of user conversation. Mentioning @cnn, however, syntactically invites discourse only from the cnn account. With a conglomerate media account such as @cnn, the unlikelihood of the account responding to this kind of unilateral discourse renders the mention as more akin to traditional media reporting on a subject—the format of the reporting does not allow or expect the subject to respond.
User Favorites, and Retweets (sources)
The last method of Twitter analysis makes use of a few fields, namely username, favorites, and retweets. By visualizing usernames by the numbers of favorites and retweets they had accrued over time, we were able to extrapolate patterns of influence. As explained below, our findings about the structure of discourse sources varied substantially between the “fake news” corpus and the “#fakenews” corpus.
“Fake news” User Influence
Within the “fake news” retweets and favorites visualizations, user accounts roughly break into two modes of influence over time: sources with sustained influence and sources with sporadic influence. Looking at the visualizations for retweets and favorites, one sees that accounts like @prisonplanet (editor-in-chief at InfoWars, beginning period 1) and @realdonaldtrump (beginning in period 2) feature prominently in terms of influence throughout our entire period of collection. Their temporal duration and consistent retweet/favorite reach informs how we understand such influential accounts as sustained sources. Whereas hashtags and mentions are a bit trickier to distance-read for sentiment, this project contextualizes the role of retweeting and favoriting compared to other Twitter functions. Proliferating content with these functions likely reflects a user’s identification if not affirmation with the tweet’s content. If this is true across the board, the dominance of conservative voices in the retweet and favorite visualizations may suggest an overall partisanship to the sustained discussion of “fake news”. The scale of our analysis makes it impossible, of course, to evaluate the political leanings for the accounts doing the retweeting and favoriting, but the trend of having just a few accounts accruing sizable degrees of discourse activity is precisely why we found this method of measuring influence so valuable.
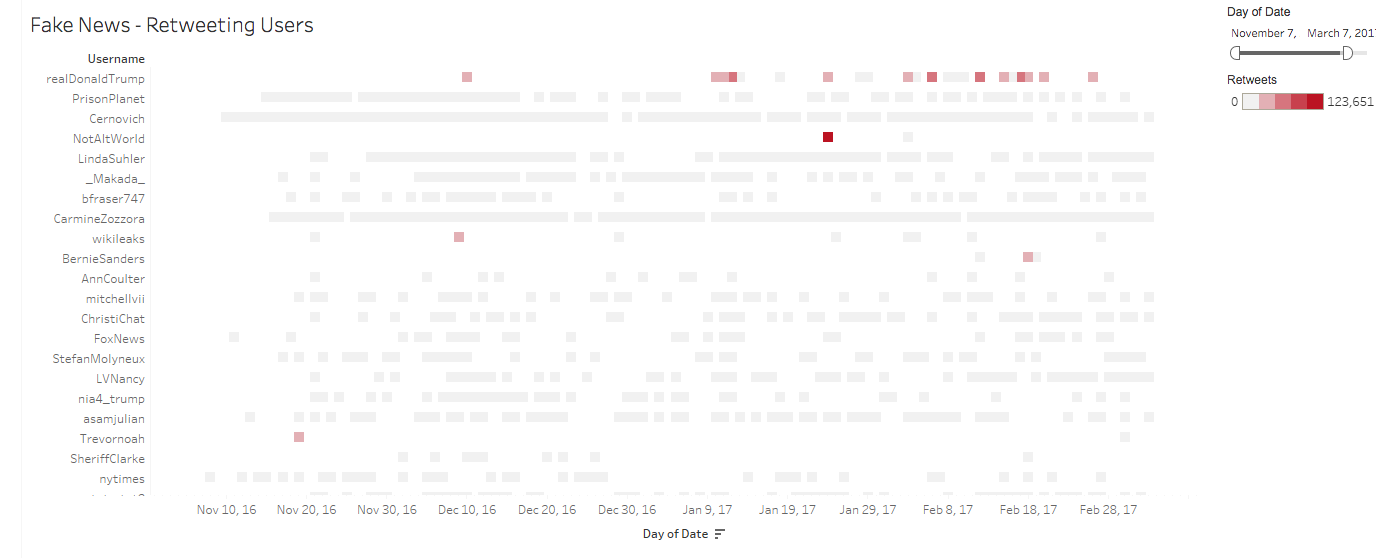
Fake News – Retweeting of Users
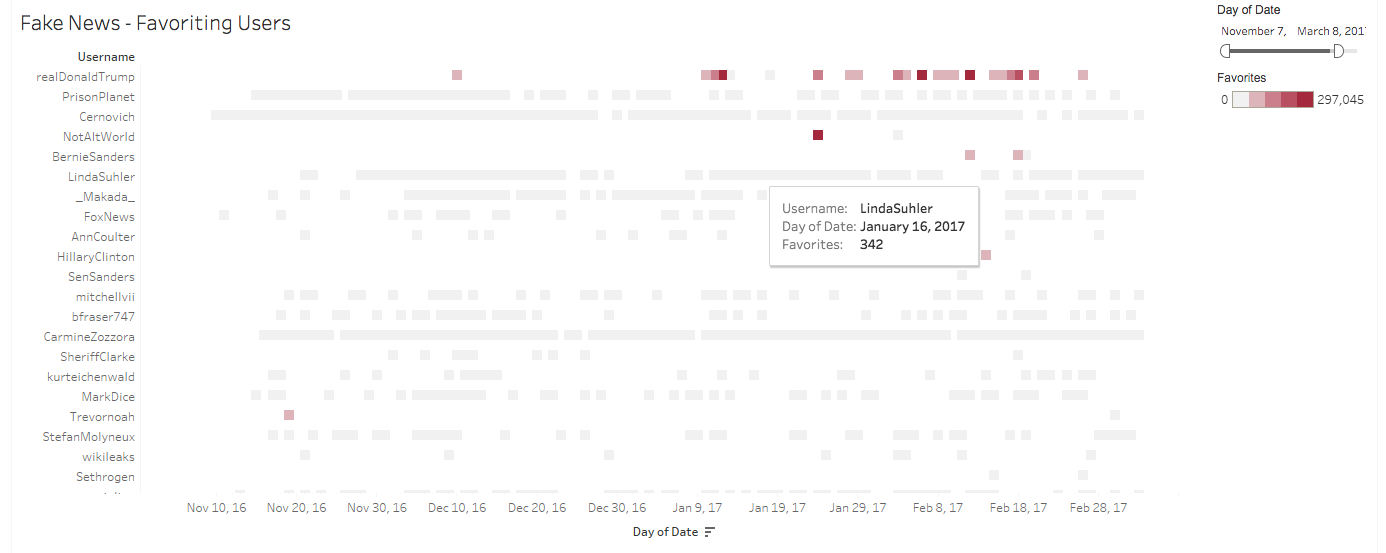
Fake News – Favoriting of Users
The distinction of these conservative voices as sustained discussion is crucial, as the “fake news” data exhibits a few key instances of significantly high retweet and favorite activity for an account on only a particular day or few days. While a prolonged influence certainly matters, in many cases these sporadic sources have just as much quantitative activity (if not moreso) than the peak days for the sustained sources. For instance, on December 9th @wikileaks peaks with nearly 27,000 retweets. This is the most active day of source activity in period 2 for retweets, and only matched by @realdonaldtrump’s very first use of the term “fake news” on December 10th which garnered 25,000 reweets. Interestingly, the preponderance of favorites for this sporadic activity is far outmatched by @realdonaldtrump: the same days show 27,000 favorites for @wikileaks and 75,000 favorites for @realdonaldtrump. Though this is but once instance, these findings suggests that there is more substantial future research as to how favorites may be used in a more partisan manner than retweets. The second fascinating moment for parsing these sporadic sources comes at the end period 4. On January 24th, a self-identified “#Resistance” account called @notaltworld accrued 123,000 retweets and 297,000 favorites for a single tweet, both numbers representing the peak for each dimension within the corpus. The tweet, which reads “Can’t wait for President Trump to call us FAKE NEWS. You can take our official twitter, but you’ll never take our free time!”, came at a historical moment in which Twitter discourse about “fake news” (#trumppressconference on January 11th) had visibly reached its peak. The explosion of discussion on Twitter, then, is seen to have fueled a newfound usage of the term in direct opposition to the conservative slant of @realdonaldtrump and sustained sources.
#fakenews User Influence
The differences between the “fake news” and “#fakenews” datasets is perhaps seen nowhere as clearly as in user trends. The “#fakenews” username dataset is mainly comprised of “individual” users, as opposed to usernames affiliated with an organization or celebrity. There are moments in time when well-known organizations or important cultural/political figures utilize the fake news hashtag, and these bright red dots punctuate the “#fakenews Username by Favorites/Retweets” visualizations. December 9th, for example, is dominated by the use of “#fakenews” by @wikileaks, garnering nearly 25,000 favorites and 20,000 retweets over the course of the day. January 10th, the only day during our data collection period that Donald Trump uses the hashtag “#fakenews”, results in 46,000 favorites and 15,000 retweets. Yet these sorts of events are largely anomalous in our “#fakenews” dataset. Arguably more influential than either of these uncharacteristic spikes in activity is the regularity of the reach of Linda Suhler (@lindasuhler). While not often the most retweeted or favorited user in each of our designated time periods, Linda Suhler is by far the overall most favorited and retweeted user in the “#fakenews” dataset, with close to 138,000 favorites and 95,000 retweets between November 2016 and March 2017. Suhler is followed closely by users @bfraser747, @mitchellvii, and @christichat, none of whom have any traditional media connections (aside from @mitchellvii’s YouTube radio station, which has roughly 11,000 followers) and all of whom are self-proclaimed President Trump supporters. This, along with “#maga” (Make America Great Again) as the hashtag most frequently associated with “#fakenews”-tweets leads one to suspect that “#fakenews” is perhaps used in a more partisan way than the “fake news” term version of the sentiment.
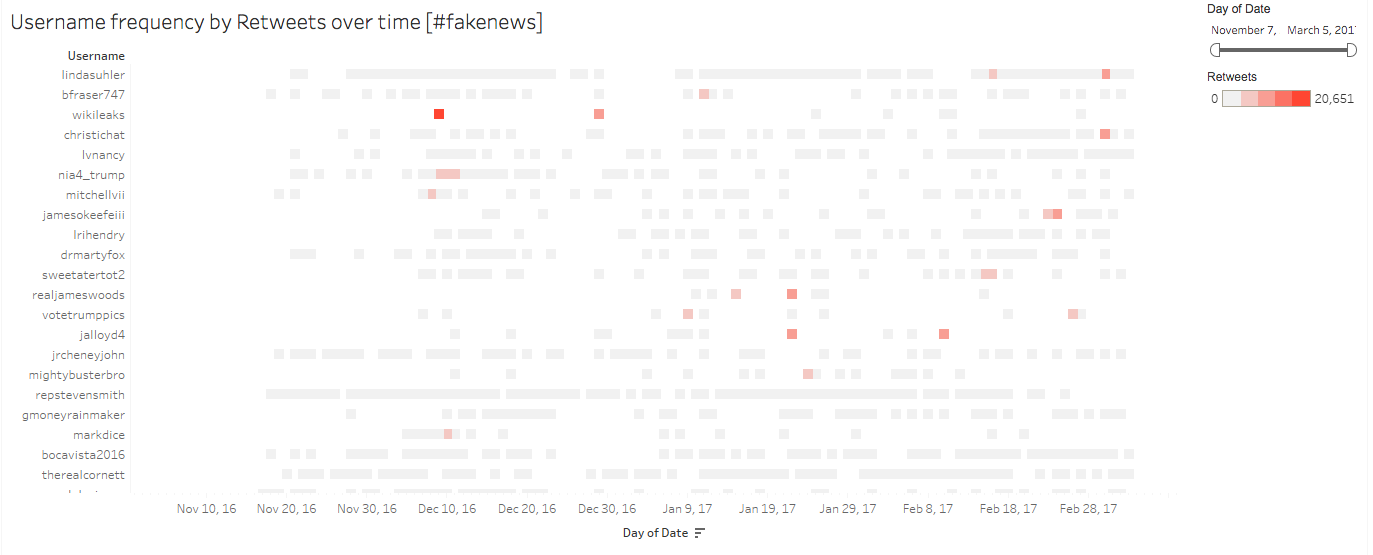
#Fakenews – Retweeting of Users
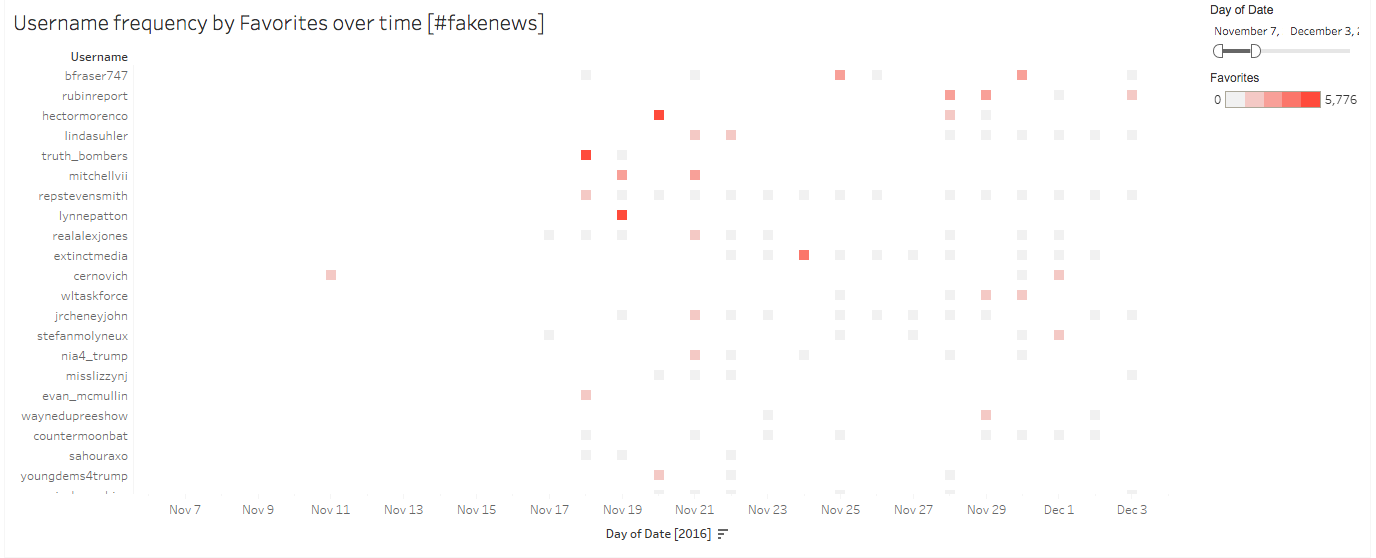
#Fakenews – Favoriting of Users