

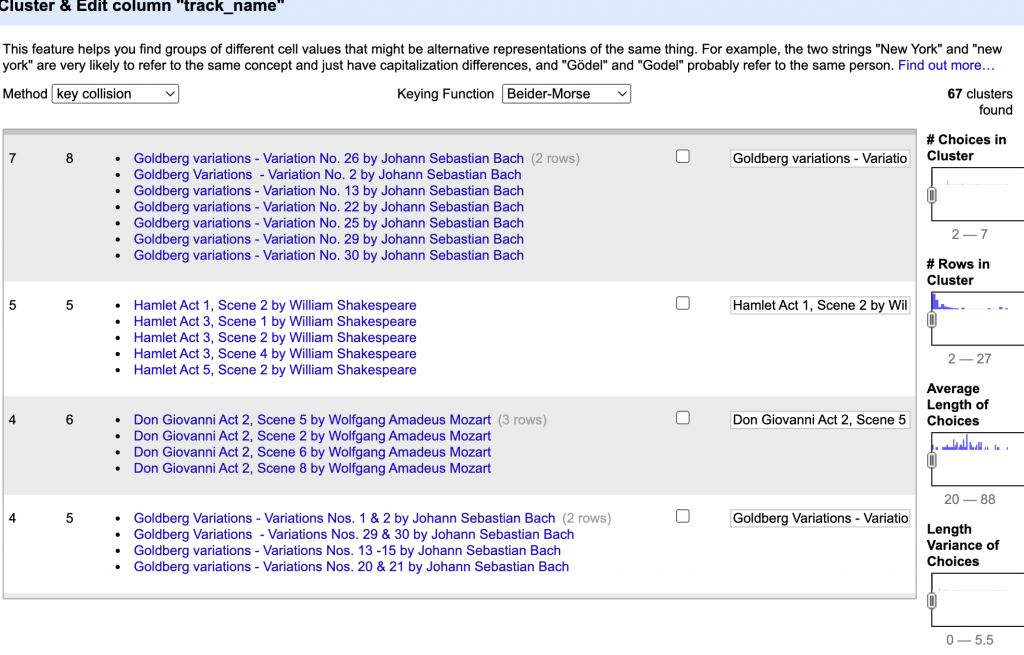
Code + files for the “trials” found here.
TRIAL 1:
- Used the whole dataset to make the first pass at creating the nodes and list: it took a VERY long time. (4+ hours, but I aborted the script before it ever completed)
- Consideration to compare 2 decades at a time (eg 1950’s to 2010’s)
- Compare 1 vs Compare 2 (1980’s doesn’t have a decade to compare to, run against itself?)
- In the data, I created a column called “Decade” and assigned values of “40s” when date = 1940-1949, “50s” when date = 1950-1959 , etc. These values were assigned accordingly: 40s, 50s, 60s, 70s, 80s, 90s, 00, 10s, 20s
TRIAL 2:
- Ran .py script to make 40-50vs10-20 & 60vs00
- Noticed that the source and target were the same:
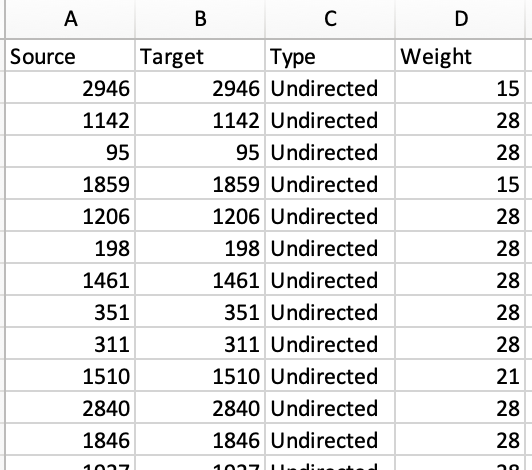
- Hypothesis on why: because using the castaway_ref as the node, these aren’t unique due to the repeat of 8 choices the castaways (std_name) make per episode. Need to identify a way to have a unique identifier as the node
TRIAL 3:
- Possible solution: create a unique identifier for each episode that accounts for the dimension of the decade and the shared choice of the artist will be the edge connecting them (had to sacrifice the std_name / castaway label for the sake of uniqueness)
- Assign consecutive numbers to the “decade” data when the “date” column is sorted oldest to newest, example:
- “Decade_episode” ID will now serve as the unique identifier. Might have to use this as a the label too (nothing unique to make identifier)
- For the “label” of “Decade_episode” ID, joined the “Decade_episode” with the “std_name”:
- =JOIN(“-“,E25439,I25439)
- 20-444-robert macfarlane
Reflection about nodes and edges formation:
- What are the shared artist (std_artist) choices between 2 castaways (std_name)
Explanation of activity between the nodes(TRIAL 1 & 2): - For (std_artist) A, they were selected as an artist of a desert island disc by castaway 1 and castaway 2. No other artists followed that pattern. The weight of “1” reflects that singularity of occurrence. However, castaway 1 and castaway 4, both selected (std_artist) C. The weight reflects that shared occurrence by the number “2”.
- Need to decide: The nodes = std_artist or nodes = castaway_ref
TRIAL 3B:
- Co-occurrences of an artist within a decade
- The blanks: total of 15 for std_artist, but they have track_name values. See below:
- Can that be incorporated into the network graph (the absence)? Maybe this can be made manually, through the process of creating a network graph of the absence?
- Tied to run the track_name through base64 decoder, (As suggested by teammate Lubov), but none of the encoding was recognizable:
- Since moving to Trial 4, it was not necessary to reconcile these values as they were not randomly selected.
TRIAL 4:
- Couldn’t get this to populate an edge table… it was just blank if I use artist as the node.
- Need to Re-do
- Selecting only 1 artist choice from each year
- Since not all the months/ dates/ or even years are present, selecting a single month- date across all the years represented in the data set was impossible (i.e. the same month-date).
- Some consideration was given to the possibility of selecting a month/day/year artist choice representation based: a monthly range or highest yield of choices on a particular month-day.
- This doesn’t result in a solution that would represent every month or every year
- New Criteria = use a randomizer tool to select an artist choice for every year. Used: https://www.gigacalculator.com/randomizers/random-picker.php
TRIAL 5:
- Noticed that the data file base I was using didn’t have the same total # for rows; DISCS-desert-island-discs-OnlyNeededFields_OpenRefined 25,459 vs 26260_DISCS-desert-island-discs-OnlyNeededFields 26,259
- Pivoted to the file with the higher amount of rows
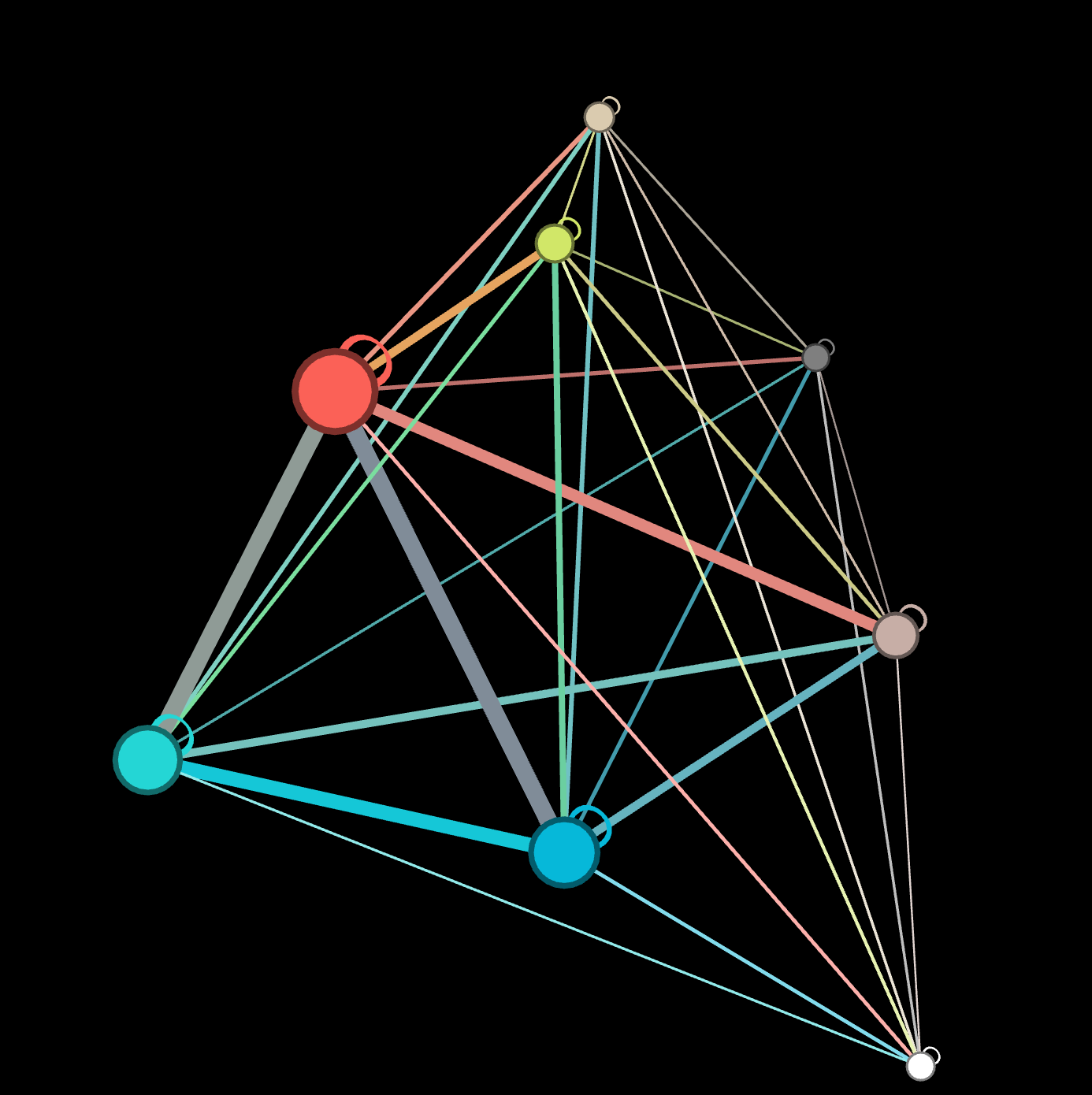
- Made artist ID’s for all the artists in the whole dataset.
- Selected just the 80’s decade to try using the new artist ID’s (as the nodes) with date as the edge
- Successful run of .py (made a weighted adjacency table)
- When I loaded it into Gephi, I got an error of duplicate nodes ( maybe due to pulling in the date they were mentioned as a choice?). I removed duplicates just on the vertices file and was accepted into Gephi without errors
TRIAL 4B:
- Moved back to a previous data processing iteration (Trial 4) and tried using the randomized selection to process using the artists as the nodes and the episode date as the edge.
- The edge list resulted in an incomplete nodes/edges list, shown below. Decided to abandon the randomized tactic.


Individual Physicalization Process
Materials:
- Foam Core boards:
- (1) Black ¼” thick
- (1) White ⅜” thick
- Recordable sound device

- Thread (Aunt Lydia’s Crochet Thread Classic 10) – 8 different colors

- Screws (various sizes) + Screw driver
- Tracing paper + pens
- Spray adhesive
- Drinking straws (regular and hard plastic versions)
- Utility + exacto knife
- Duct tape






