

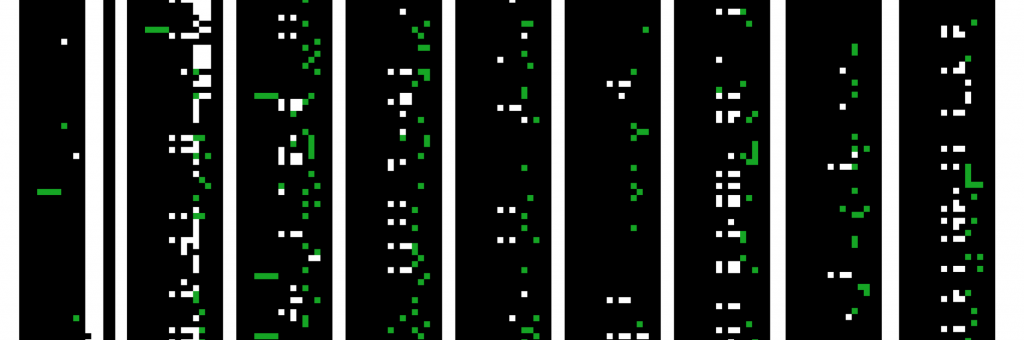
Catherine D’Ignazio and Rahul Bhargava define data literacy as: “the ability to read, work with, analyze and argue with data as part of a larger inquiry process. Reading data involves understanding what data is, and what aspects of the world it represents. Working with data involves acquiring, cleaning, and managing it. Analyzing data involves filtering, sorting, aggregating, comparing, and performing other such analytic operations on it. Arguing with data involves using data to support a larger narrative intended to communicate some message to a particular audience” (2016). For my project, “Special Characters,” I sought to explore the early stages of data literacy, namely the process of standardizing a third-party dataset once acquired. We find that in Digital Humanities and data-driven research broadly, information is represented and communicated at the level of output – typically as a visualization of key results. The final product of data analysis is what is communicated and is the thing that is apprehended. As Ashley Reed writes, “The thing-that-is-made stands as both the object of study and the repository of all evidence regarding its own production, effacing with its solid thingness the ephemeralities–including the conditions of care– that made its production possible” (2022). Though Reed was speaking of the fetishization of output in androcentric maker culture, she is articulating a similar sentiment as the principles of data literacy and data feminism that aim to demystify output and emphasize how data is collected, manipulated, and sieved to tell certain stories. The process of how such stories get told remains invisible. The “Special Characters” project materializes an aspect of “working with” the Desert Island Disks Dataset, which has many instances of erroneous special characters that translate to diacritics. It takes the form of a barbell that can be customized with various size weights that represent the frequency of special characters in the dataset. The special characters render the information unusable in its current state and therefore necessitate further processing before running any analysis. Just take a look at the Data Map and Key and you will see the smattering of green blocks that correspond to cells in the dataset containing special characters.
The purpose of the “Special Characters” project is to reveal the active, laborious, and human effort that goes into working with data. Luci Pangrazio writes, “Imagined as immaterial, data is thought to be more responsive, adaptable and mutable, and therefore ready to fulfill the demands of a datafied system” (2020). “Special Characters” aims to refute this claim, demonstrating our experience as researchers as we found the state of the data insufficient for our purposes. Because much of the data was initially inoperable, it required a lot of time and effort to transform and standardize.
This project is meant to be interactive. People are intended to match a special character pair with its corresponding weight (see table below) and lift the barbell in order to perform an abstracted representation of the labor required in working with a dataset. There is a large body of research about how physicalization is a productive way to introduce people to activities around data collection, processing, and representation (Hogan et.al, 2023). This project builds upon that research by presenting a way to physicalize and experience the process of data maintenance, illuminating the often obscured activities in the critical initial phases of data-intensive research. Inspired by “experiential prototyping”, a reflective, playful practice “at the intersection of hands-on practice and critical making,” “Special Characters” is a pedagogical tool that fosters an alternative, affective mode of learning about data-driven research, encouraging understanding through physically deconstructing and reconstructing a material object that stands in for the digital (Mauro-Flude, 2019). This allows participants to experience the data at a small scale– at the level of one’s body and movement. This intimate scale is, as Brian Holmes illustrates, “irretrievably weighted down in our time, burdened with data and surveillance and seduction, crushed with the determining influence of all the other scales” (2009). A desired outcome of this project is that participants will realize the generative possibilities of understanding at the level of hands-on making.
Digital Humanities has a great potential for experimentation and performative, material methodologies. By physicalizing the invisible labor undertaken by humans in the process of digital computation, we can begin to think critically about how our technological world communicates information as static, precise, and self-contained. With the “Special Characters” project, I hope to contribute another way to represent and recreate the experience of “working with data” and echo a data feminist ethos that process is productive and worthy of representation in and of itself.
The Lifting Process
The special characters occur in the dataset as a combination pair that translates to a diacritic or a non-Roman character. This mistranslation likely occurred because the initial Python webscraping misinterpreted a UTF-8 encoding system as MacRoman.

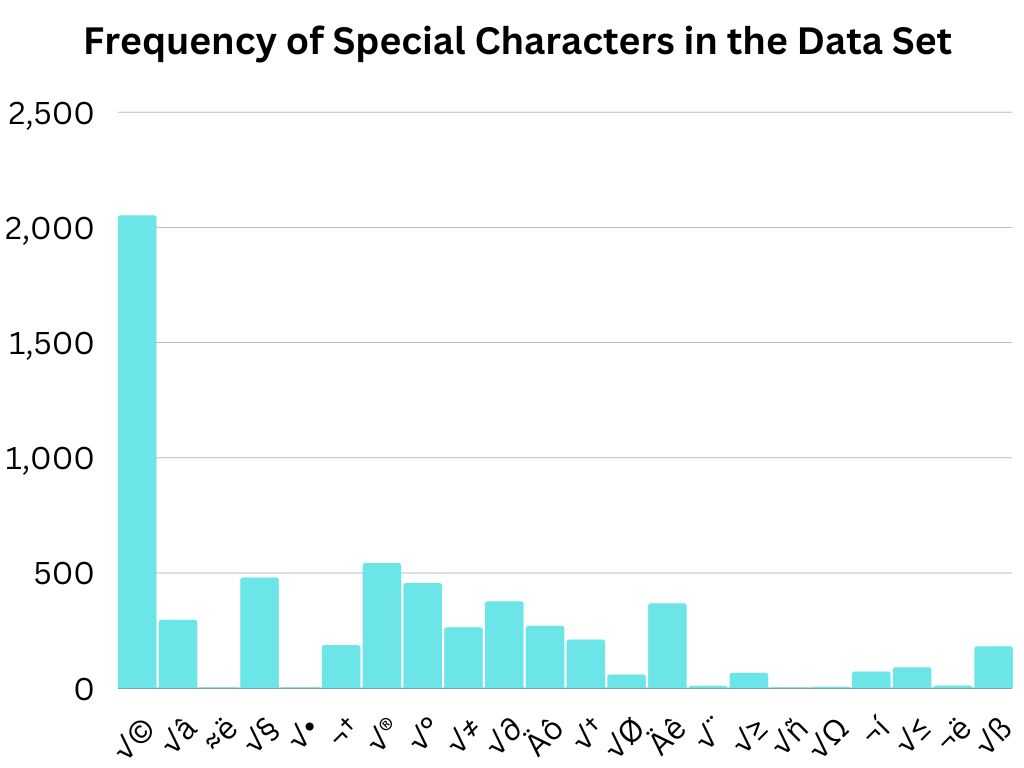
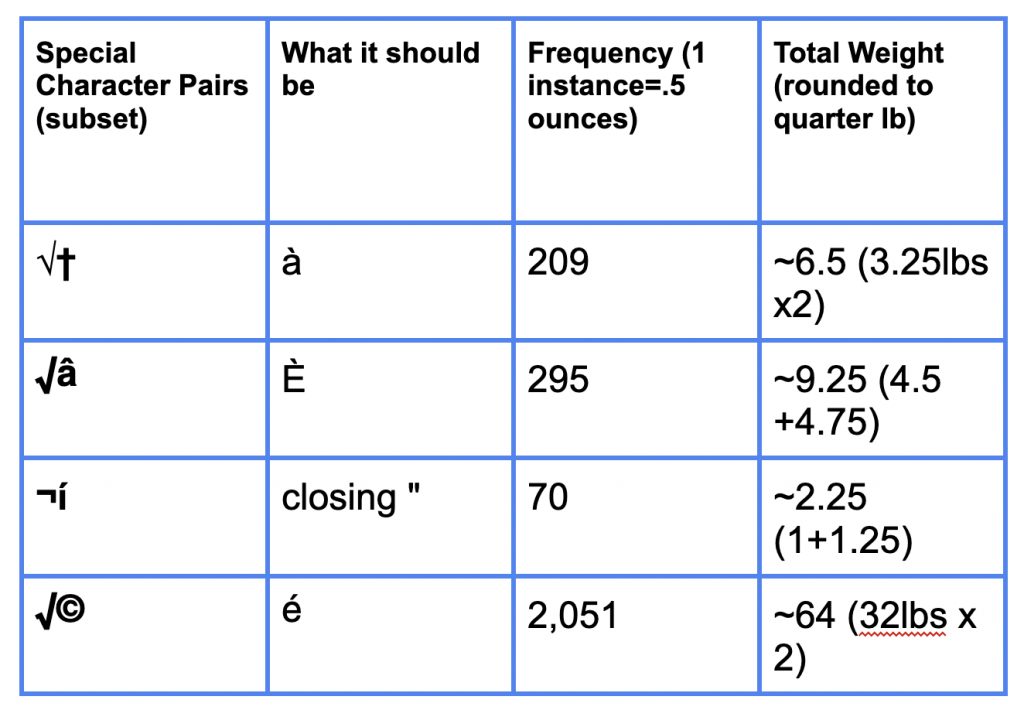
There are 23 special character combinations occurring at various frequencies. The frequency is represented as weight with the relationship 1 instance = .5 ounces. See the table below. This sampling of special character pairs can be built by affixing various size weights to the barbell.
Technical Details

Given constraints of time and resources, I decided to materialize only one aspect of the missingness map– there are also issues with name standardization, absent data, etc. As mentioned, the special characters are a result of the creator of the dataset conducting a Python webscraping of Wikipedia information, which pulled certain string literals that were not able to be interpreted by the program, resulting in special characters. For instance, Édith Piaf, one of the most frequent artists that castaways said they would listen to on a desert island, causes a problem in the dataset (Gustar, 2020). The capital letter “E” with a left-leaning, or “grave” accent mark (È) is translated into “√â” and occurs 295 times.
In order to find all the possible diacritics in the DIDD, I manually appraised the dataset and used this resource on StackOverflow that fellow teammate, Jessika, came across. I then did a simple “Ctl+F” search to learn how many times a certain special character pair occurred. Some combinations were on the list and could be referenced in the dataset and confirmed to be mistranslations of letters such as “ä”, “ç”, etc. Other special combinations were not on the list and occurred in the dataset with Eastern-European names like Leoš Janáček and Antonín Leopold Dvořák. I found 23 kinds of special character pairs. Respective frequencies in the dataset ranged from occurring once to 2,051 times.
At first, I hoped the relationship between special characters and weight could be 1:1 (i.e., a diacritic pairing that occurs 350 times would be 350 ounces), but quickly learned that method would be impractical, expensive, and physically difficult to make and transport. I settled on the relationship as 1 instance of a diacritic pair would equal .5 ounces.
Materials & Methods:
- fabric (normal embroidery cloth)
- hot glue gun
- needle and thread
- playground sand
- a dowel
- a scale
To make the weights, I used a template for a DIY stackable ring baby toy (Your baby will be obsessed with these DIY stackable rings). The pattern worked for my purposes because I needed concentric circles with a center point. Instead of stuffing the ring with cotton, I used playground sand purchased from Amazon. To follow this project’s tropical theme, I decided sand would be a good material to work with to materialize the mess–literally. As I went along, I realized that sand also mimics the process of appraising and altering data – sand is unwieldy, difficult to contain and shape, easily falls through cracks in its container, and difficult to see unless in aggregate. (I think I might still have sand in my hair.)
I made 13 sets of weights: 3 sets of 2lbs, 3 sets of 1lb, 2 sets 0.5lb, 1 set 0.65lb (this was my first test, so the weight was random based on how much sand it took to fill the ring), and 4 sets .25lb. There was no real rationale when determining how many sets I would make. However, knowing that most special characters occurred around 200-500 times in the dataset, I made sure my weights would be able to add up to various amounts within a 9lb-15lb range.
I used a scale to precisely measure the weights. I chose the various weight amounts out of necessity; I had to round to the nearest quarter pound so that building multiple different frequencies could be done with the same standardized weights.
Then, I made a key identifying a sampling of character combinations and their corresponding weight that participants can affix to the bar and lift!
– Ava Kaplan