Heard about APIs, but still not really sure what they are or how to use them? This post will take you through:
- the basics of what an API is
- when you might want to use one
- what kinds of institutions or collections might have APIs of potential interest to DH practitioners
- where to look on these sites for access to APIs
- how to construct queries, and
- what to do once you’ve received some data!
What’s an API?
An API, or Application Programming Interface, is, in general, a defined way for different parts of software systems to talk to each other. A software system is made of many individual parts that must work together to respond to commands or requests. When humans need to talk to each other, we try to use a language that all parties involved can understand, and that language has rules and guidelines that govern how we form words and sentences with particular meanings. Similarly, APIs are built with rules that must be followed for successful interactions.
Often computer programs will communicate with each other using APIs in a way that is not visible to humans. However, humans can learn to directly create requests and receive information in a readable format using APIs, and this can be a powerful way to access data. If you want to use one to gather data for a digital humanities project, this will be done through interactions with web APIs.
You may see frequent mention of REST (Representational State Transfer) or RESTful APIs, which are the main focus of this tutorial, though other, more complicated approaches to building web APIs exist. RESTful APIs make use of a familiar way of browsing the web—Hypertext Transfer Protocol, or HTTP methods. You can use these kinds of APIs to get, post, or delete data online, but this tutorial will be focused mostly on creating GET requests and receiving responses, something you probably already inadvertently do every day.
A request is made with a URL, or Uniform Resource Locator, and sent to a web server using HTTP with the expectation of getting a response back in the form of human-readable text or data, or simply a web page. The URL supplies the web server with everything it needs to create and return a correct response. See the “How do I construct a query?” section below to read more about how to piece together a URL in order to return data that fits particular parameters.
When would I use an API in the context of DH?
APIs can provide a way for you to request and receive specific bits of data that interest you from large corpuses of information from cultural heritage organizations and other data creators. That data can come to you in a predictable and machine-readable format, such as JSON or RDF, and will be broken up into metadata categories chosen by the institution that created the data.
APIs can be of use if you want to download some data—not everything available on a website, and not an individual record or two—and you are at least somewhat familiar with the available information and the metadata used to describe it, and know what you think you are looking for. In many ways it’s like using an advanced search function, except instead of a results page with a user interface to scroll through, you can get neat chunks of data that you can then further refine and manipulate.
APIs can also enable the possibility of continuous retrieval if data that fits your parameters is frequently updating. This is generally how developers use APIs—it’s a way to get to the data repeatedly and pull it into apps or programs without having to go through a user interface. Instead of going back to a site and performing the same search every week or every day in hopes of finding new information, you can create a script to programmatically query an API at a certain rate, automatically returning any data that fits your parameters.
Why are APIs being embraced by libraries, archives, and museums?
They’re a way for institutions to make their collections more accessible for things like DH projects by making data about them machine-readable and queryable. Making semi-structured data available provides flexibility, and many institutions hope this will encourage innovative or unexpected uses of their collection information.
Organizations can also leverage APIs, either their own or other organizations’, to more automatically provide or enhance access on their websites. For example, libraries that use the open source library system Koha can use an Openlibrary API (part of the Internet Archive) to find and display images of book covers in their catalog, without having to individually search for each book cover and then download and upload the picture.
APIs are at the heart of the Cooper Hewitt Smithsonian Design Museum’s website, and can return everything from collection information to descriptions of temporal periods to a list of relationship terms they use to connect people associated with the collection. Even their cafe hours can be returned by querying an API! Not only does this mean their website can display the accurate hours, it also means sites like Google Maps can use that API to pull in information about their hours at a certain rate. If the cafe were to be closed for a holiday, that change would be reflected in the data available via the API.
Where can I find an API?
Certain types of cultural heritage organizations tend to make their data available via APIs, namely larger libraries, museums, and archives with vast amounts and varied types of data to share, and a budget with which to provide access. Large digital libraries and other sites that aggregate digital resources across collections are also good candidates. National and local governments, social media sites and online comments sections, and ongoing creators of primary sources like newspaper companies can also provide a wealth of information for digital humanists through APIs. Having a large amount of data might make a bulk download too unwieldy, and for many of these institutions, their users are more likely to be interested in a small portion of the data rather than everything available, making a public API a worthwhile service.
In addition to size, it can be helpful to look for sites or institutions with stated commitments to openness or open access. Information sharing on some level is legally required for many government institutions (and projects that receive government funding), plus they have a lot of data, which is why they’re a reliable source of APIs (remember national museums and libraries fall into this category!). On the other end of the openness scale, rich, giant resources like proprietary databases are unlikely to give you access to their data through an API. The information and its organization is their product, and there is a fear that you could scrape it all using an API and remake and redistribute their database. Companies may be willing to work with you if you need access, but it could cost a significant amount of money or come with restrictive use or distribution parameters.
Individuals or creators of smaller projects can also construct APIs if their amount of data justifies it or if they want to provide access to frequently updating data. The open access publication, Debates in the Digital Humanities, for example, makes available APIs that can return all keywords or all sentences marked as “important” by users.
However, APIs can be cost and labor intensive to create and maintain, so access to machine-actionable data from less well funded individuals or organizations is often differently provided, if at all—possibly as some sort of data dump, or file with bulk amounts of information in a CSV/TSV or other format that you can download. The Carnegie Museum of Art collection data is available on Github, as both a CSV and a JSON file. While you do have to download information about the entire collection, you could then “query” the data afterwards by loading it into a program like OpenRefine and searching for and retaining data of interest. Some organizations will provide an API and a bulk download option, to cater to different access needs.
No really, where can I find them?
While many websites provide access to data using APIs, they aren’t often so easy to find. If you suspect a website may have an API available for you to use, try looking through the site’s navigation menu for words like “Developer”, “Pro”, or “Tools”. Don’t be put off by the terminology: if the APIs are publicly accessible, they are for anyone to use.
How do I construct a query?
Once you’ve found a website with a collection you’d like to further explore and an API with which to explore it, your next step is to check the documentation. Many of the APIs created for collections of interest to humanities scholars have robust documentation, often with beginner and more advanced level instructions. Even after you’ve become a confident user of a particular API, it’s a good idea to always start with the documentation page, as the design of an API can change over time.
To start, not always, but often, you will need to request a key or form of identification or authentication. While some APIs are completely open, free, and available for the public to use or test as they please, most have some kind of barrier to access in place. Often you’ll have to provide an email address or sign up for an account, and then you can put in a request for a key, which is simply a string of characters assigned to you that will be used to authenticate the requests you make. The access granted by your key will probably come with rate limits that will prevent you from making a large number of requests in a short period of time. Some APIs require multiple keys, Secrets, or other forms of authentication in order to make requests.
Why put these barriers in place? Institutions need some control over who is accessing their data and how, to guard against malicious users and people who want to overload their systems with requests. APIs can be used to post or even delete data from a site, and an institution may use a single API for internal and external users. In these cases, the keys safeguard against users being able to access all functions of the API.
Once you’re signed up and the necessary authentication is received, you can start to build a query! Again, the API documentation will cover the exact structure and syntax that the request needs to adhere to, but most REST queries follow the same general pattern:
protocol://base_url/resource_path?parameter_key=value&api_key=<your_api_key>
What does this look like in practice? Below is a simple example from the Digital Public Library of America’s (DPLA) search API:
https://api.dp.la/v2/items?q=fruit+AND+banana&api_key=
Protocol: HTTPS, or Hypertext Transfer Protocol Secure, which encrypts the traffic between your machine and the web server. Remember all REST APIs operate using HTTP.
Base URL: The domain name, as specified in the documentation, which will always form the base of your query. Often these will include several terms separated by forward slashes. The “v2” here refers to the API’s version, in this case version two.
Resource Path: The resource path is the first part of your specific query, and is followed by a question mark. The DPLA search API has two resource paths available: items, used here, which will return data about individual resources, and collections, which will return data about groups of items.
Parameter/key-value pair: The key here is “q”, which in this API indicates we want to search all text fields. Boolean variables can sometimes be used as shown, to search for items with the corresponding values “fruit” and “banana”. Multiple parameters are separated by the “&” symbol. Depending on the API, you may be able to specify format here as well (format=json, for example). In this case, no specification was necessary as this API only returns JSON.
API Key: Here you will enter your API key if one is required, in the format specified.
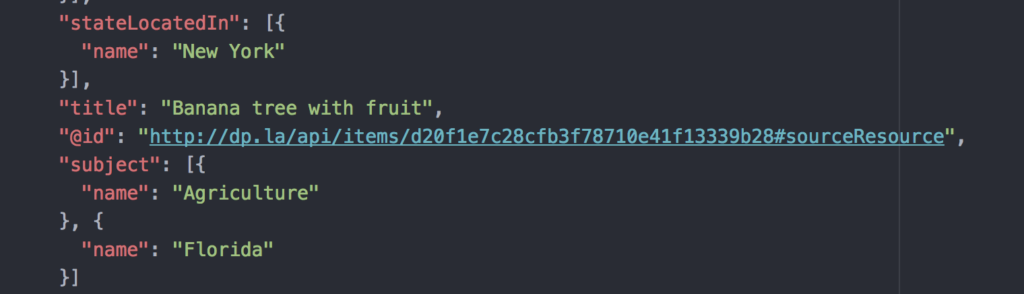
If you type that URL into your browser (with your own key, of course), this will return a JSON file with…a lot of metadata—almost 200 lines per item if the JSON is pretty printed, or more nicely formatted for human reading. It’s a bit overwhelming, but if you start to scroll through, you can begin to note the key-value pairs (also a part of JSON files), and pick out certain categories of data that might be of use in your research, such as the “title” or “subject” of each item.
Side note: DPLA’s API documentation, where this example query originated, is thorough and very beginner friendly—it’s a great place to start exploring.
No matter how complex or well constructed, your request will only return data that’s as good as the metadata that’s been put in, and will reflect those categories that the institution has decided upon. The API will also only return information about what has been deemed worthy to collect and digitize or digitally describe by the institution in the first place. Even further, APIs are constructed by people based on what they think you want to retrieve and what they’re willing to provide access to, so institutions will often have multiple APIs if at all, and all operate a little differently, again, like different languages use different syntax and grammar.
In the beginning of a project, you may find the highly defined modes of access with an API to be limiting, as the categories relating to your research ideas may not directly be queryable. Still, it can be worthwhile to start broad and see what you get — though they’re designed for highly specified access, APIs can be really great ways to explore the back end of a collection! Of course, if you know exactly what you need and have an API that can provide that information, it’s only a matter of constructing a query that reflects your specific needs. While you might initially be constrained by the predetermined organization of the data, once you have some data in hand you can isolate certain categories, and add more if you plan to create or connect it with other data.
Constructing queries with Chronicling America
Let’s take a look at and construct queries using the API from a corpus of newspapers as if we were in the brainstorming stages of a DH project. Chronicling America is a resource created by the National Digital Newspaper Program (NDNP), which is jointly sponsored by the Library of Congress and the National Endowment for the Humanities. It provides access to metadata about American newspapers from 1690-present, and newspaper pages with OCR’d text dating from 1789-1963. Their API is built for general use by the public, with no key or sign up needed. It is essentially just a more direct way to interact with their advanced search function, plus it can give you access to metadata in a more usable form.
Say you’re interested in looking through Alaska newspapers for discussions of suffrage that were happening there the early 1900s. You think you might want to do some kind of text or sentiment analysis of the content you find, but you’re not sure what the final form of the project will be, whether a visualization or an interactive website or some kind of digital narrative.
To look through the digitized pages, we can add search/pages/results/? to the protocol and base URL, and then build out our query with parameters to eventually get something like the URL below, which will give us pages from newspapers published in Alaska, from the years 1912-1916, sorted by date, that include the term “suffrage”, all in a JSON file.
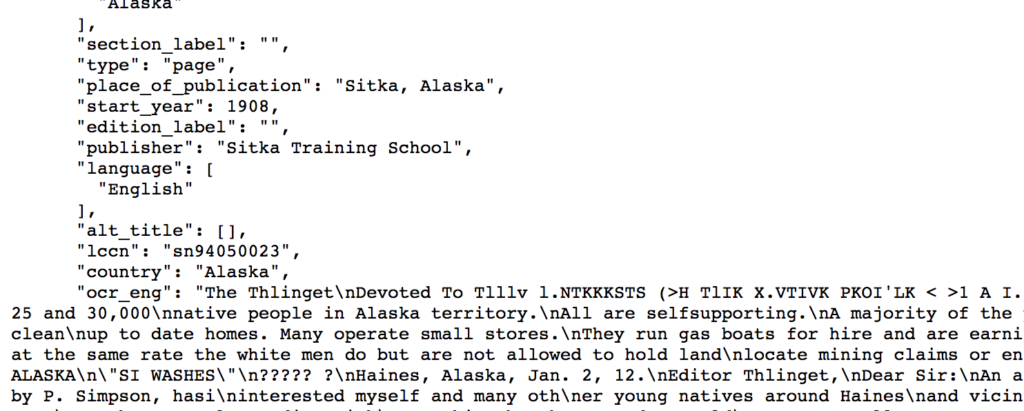
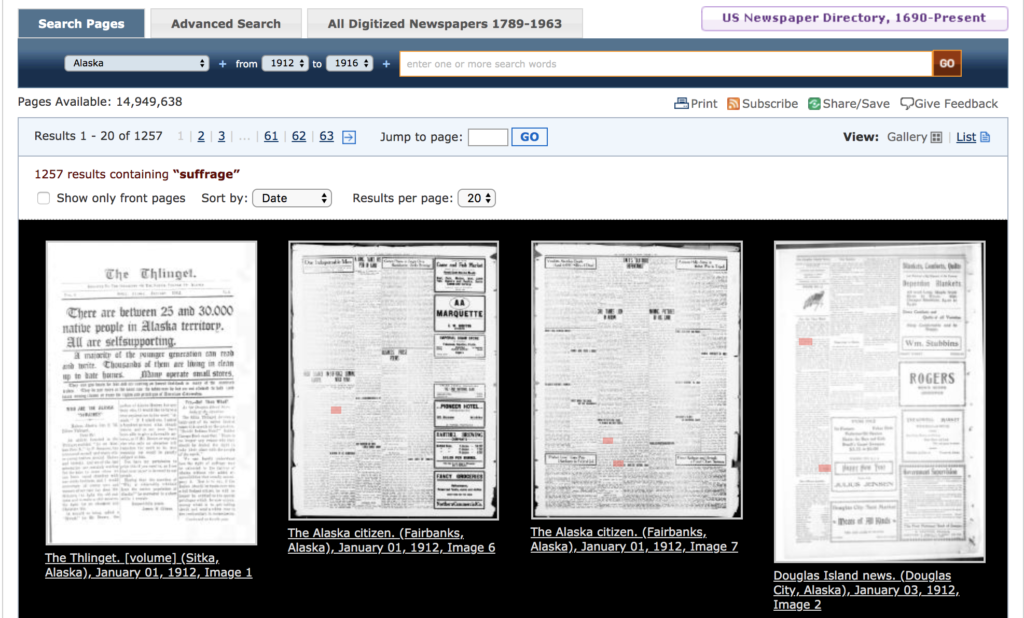
How did I know which parameters we could add? The documentation unfortunately doesn’t provide a convenient list of options. I puzzled through building the above query by first performing various advanced searches, and made note of the parameters listed in the resulting URL. I then modified this to build the query, essentially just deleting from the URL the superfluous parameters where I didn’t specify anything, adding the “sort” key to indicate that I wanted the results sorted by date, and specifying the format at the end.
But wait—there are only 20 results returned here, even though over 1200 items matched the search!

To get to our next batch of results, we’ll need to add a key-value pair for pagination, and continue re-requesting with increasing page numbers:
You now have some data—hooray! Because there is no one way to do research, what follows will be a lot of questions, like:
Is the date range sufficient for your project, or should you expand or narrow it?
Should you expand your search to also look for the words “vote” or “voting”?
Which metadata categories are relevant for your project, and are there any categories you’d like to add?
How much of the text do you intend to keep?
Would you like to have links to the images of each page in addition to the snippets of the OCR’d text?
Are you interested particularly in white women’s suffrage and/or the suffrage of indigenous people, both of which were up for debate in Alaska around this time?
Whose views are represented in these newspaper articles, and are these the views you’d like to focus on?
Looking through the text, not all of the sources discuss suffrage in Alaska, but report on different campaigns for voting rights across the country—are these outside the scope of your project?
Are there then newspapers from around the country that you can find that discuss suffrage in Alaska at this time, and should those be considered?
Do you want to search for other types of sources in other collections, such as diaries, pamphlets, or images, that also discuss this subject?
These questions and more can start to guide you towards new searches, and help you narrow your topic and pinpoint exactly what it is you are looking for, assuming it exists to be accessed.
Maybe you find you are more interested in the views on suffrage from a single newspaper: The Thlinget, which was published in Alaska from 1908-1912. Each title in this database has been assigned a Library of Congress Control Number (LCCN), which you can find in the JSON file we just received, or find by using the newspaper directory search.
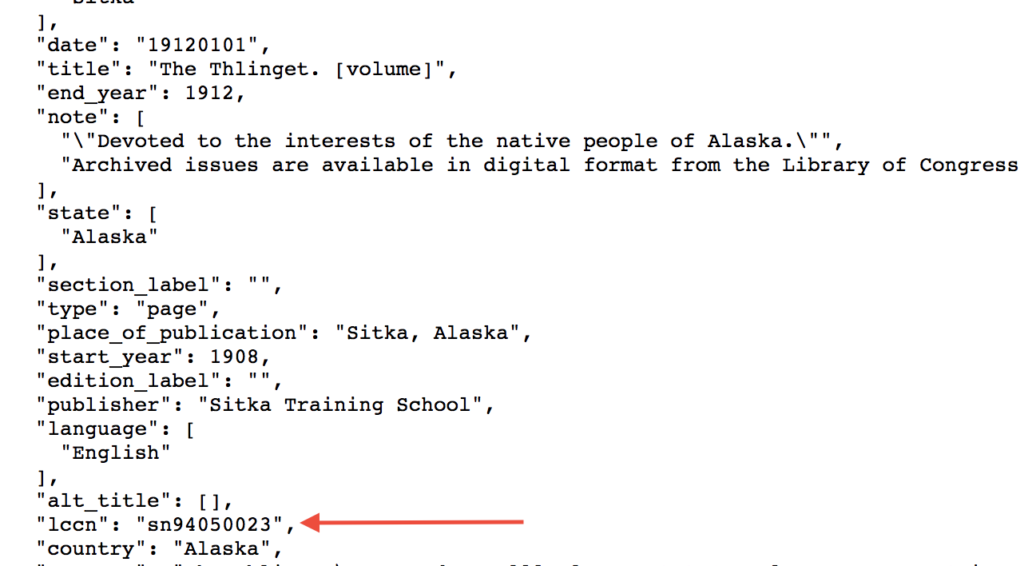
You can then can go back to using the page search to look for individual digitized pages using the corresponding LCCN, adding parameters for a date range, specific words in the text, format type, or to sort by date, etc.
Note that rather than a Boolean variable, as with the DPLA API, here a different key is used to indicate that we’re searching for either “suffrage” or “vote” within the volumes of this particular title.
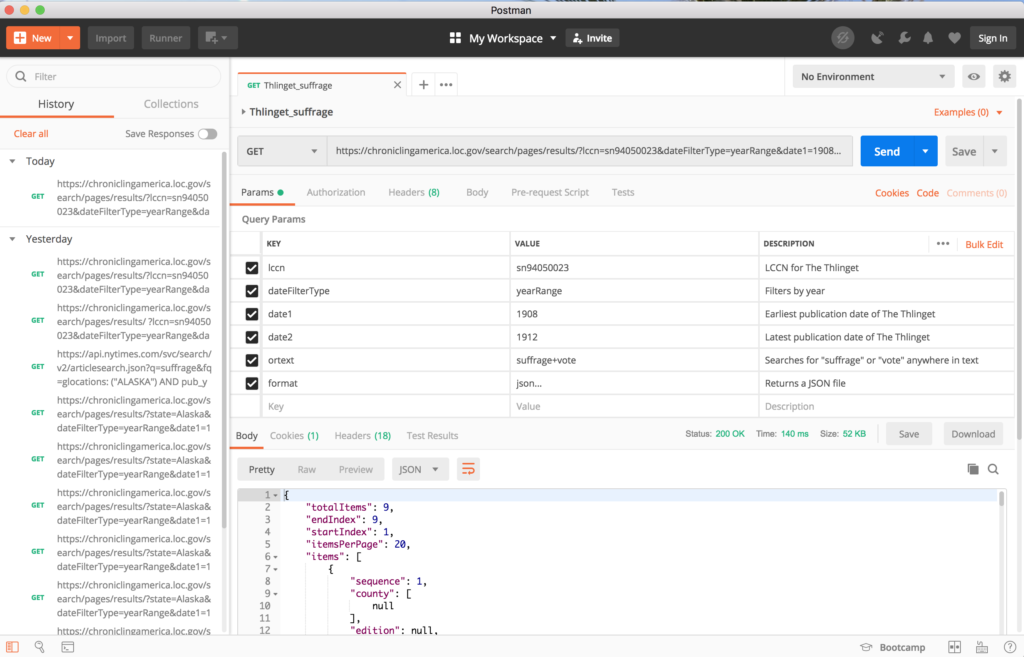
In addition to making requests directly in browser, I decided to also try another tool built for developers called Postman. You can use it to make API calls and download the data returned, and to name and save useful queries rather than having to rewrite them every time. You have the option to describe the key-value pairs of your queries, too, so that you remember exactly what each one of them does. Postman can also take those queries and generate a snippet of code in various languages such as Python that will perform the calls, and could be incorporated into more complex commands. If you want to eventually create and document your own API, you can also use Postman to develop and test it out.
Below is the more specific request executed in Postman:
Now what?
Once you’ve honed your research question and gathered some data, you need to figure out how you want to further refine your data to better explore your question. Your next steps will depend on how you want your data to be structured, or what format you need it to be in to work with various tools.
Often folks creating DH projects will prepare their data in one or more CSV files, but JSON is generally too nested and complex to be directly converted to a CSV, which only works in two directions. You can, however, use a processing tool on the command line such as jq to manipulate and extract relevant data from JSON files, which you can then use to build a CSV. Below are a few tutorials to help you better understand arrays and the arrangement of data in JSON, and how to use jq to return certain bits of data from within them.
Tutorials:
JSON on the command line with jq
OpenRefine is a tool you can use to clean your data. It records the actions you take in a JSON file that you can then export and store as part of your documentation. If you don’t want to work with command line tools, OpenRefine can also be used to parse a JSON or XML file, which can then be converted to a CSV. This Programming Historian tutorial covers how to build more advanced API queries, including instructions on how to query the Chronicling America API directly in OpenRefine and then manipulate the returned JSON data. It will then take you through steps to better match or separate the data to columns, and remove data not of interest.
If you found data you wanted online, but no API or direct download option, you can also try web scraping, which is often done with Python and Beautiful Soup.
Tutorials:
Web Scraping: Creating APIs Where There Were None
Programming Historian web scraping tutorials
When embarking on a project, remember to harvest and reuse data responsibly. Consider not just copyright/licensing and the potential load you are placing through your requests, but ethically what you should share and how—particularly if you plan to work with social media data. Often we work with information that represents aspects of the lives of people—it’s never just a number or cell in a spreadsheet.
Recording what you asked for from where, and how you came to get the particular selection of data that you received can also help you better communicate the scope of your project and make clear to your users why certain data might not appear. Your manipulation and reuse of the data is a part of its changing lifecycle. It’s important to record what you do and why as you refine and add to the data to further that transparency and allow future users to then build upon your research.