What it’s All About
What makes a museum popular? This is the question I attempted to answer through the use of a network visualization. While many might generally know which type of museum they like to frequent, many might not know how these museums are related. With this question in mind, a dataset was explored in order to understand which topics the country’s most popular museums cater to and to understand how these topics are connected.
Part of a Larger Whole
These questions pose the first step in a larger project to identify what themes are associated with positive museum ratings. Through this research, I hope to understand what expectations museum visitors have and how these expectations might be met to create favorable experiences. The visualization below is therefore intended to be part of a larger deliverable which will be a series of illustrations intended to make it easy for exhibit designers and museum practitioners to understand how to best serve the public.
Getting Inspired
Before beginning this process, other visualizations were consulted.

I found that good examples of network visualizations in the museum field are hard to find. Those that are related to museums are hard to interpret with visualizations that make communication difficult. For example, the visualization above is too condensed and would have done well to have the nodes further spread while increasing the readability of the text.
The Process
- Finding
I consulted the website Kaggle, a crowdsourced platform for hosting datasets, and chose to work with data scraped from TripAdvisor. The dataset itself contained multiple files including data related to both US and global museums. For the sake of this visualization, the data was trimmed in order to only focus on US based museums.
2. Cleaning
I decided that I’d work with the data related to museum descriptions in order to understand whether there was any similarity between museums which had high TripAdvisor ratings (5 stars on a 5 star scale). I first trimmed the data to ignore all data related to museums of less than five stars. I then focused my analysis only on the description and parsed these descriptions in order to only focus on keywords. This was done by first deleting all verbs, adjectives, and adverbs to leave only nouns. Common nouns and phrases pertaining to museum names and opening hours were then manually removed from the data. OpenRefine was then used in order to ensure that similar words were matched (a crucial step when creating a network).
3. Preparing
This data required a three step process that was necessary before the data could be brought into Gephi – a network analysis tool. The first step in this process was done through Excel where I broke the key terms I had found into separate columns and removed any header text.
4. Transforming
Once the data was prepared, it was bought into RStudio where I was able to transform the data into nodes and edges. This process made it clear which connections existed between the data. Nodes became the key terms and edges became the number of times those words were connected to others. Columns were rearranged to make it simple for Gephi to process and were then exported.
5. Visualizing
The data was then brought into Gephi and nodes and edges were identified. After this process was done, a cluster of data was seen. The first thing I did when working with this data was to color the nodes based on degree – showing me which words were most commonly related to other words. After this, I followed the process outlined by Martin Grandjean.
My next step was to apply the Fruchterman Reingold function which used the principles of gravitation to define communities of nodes.
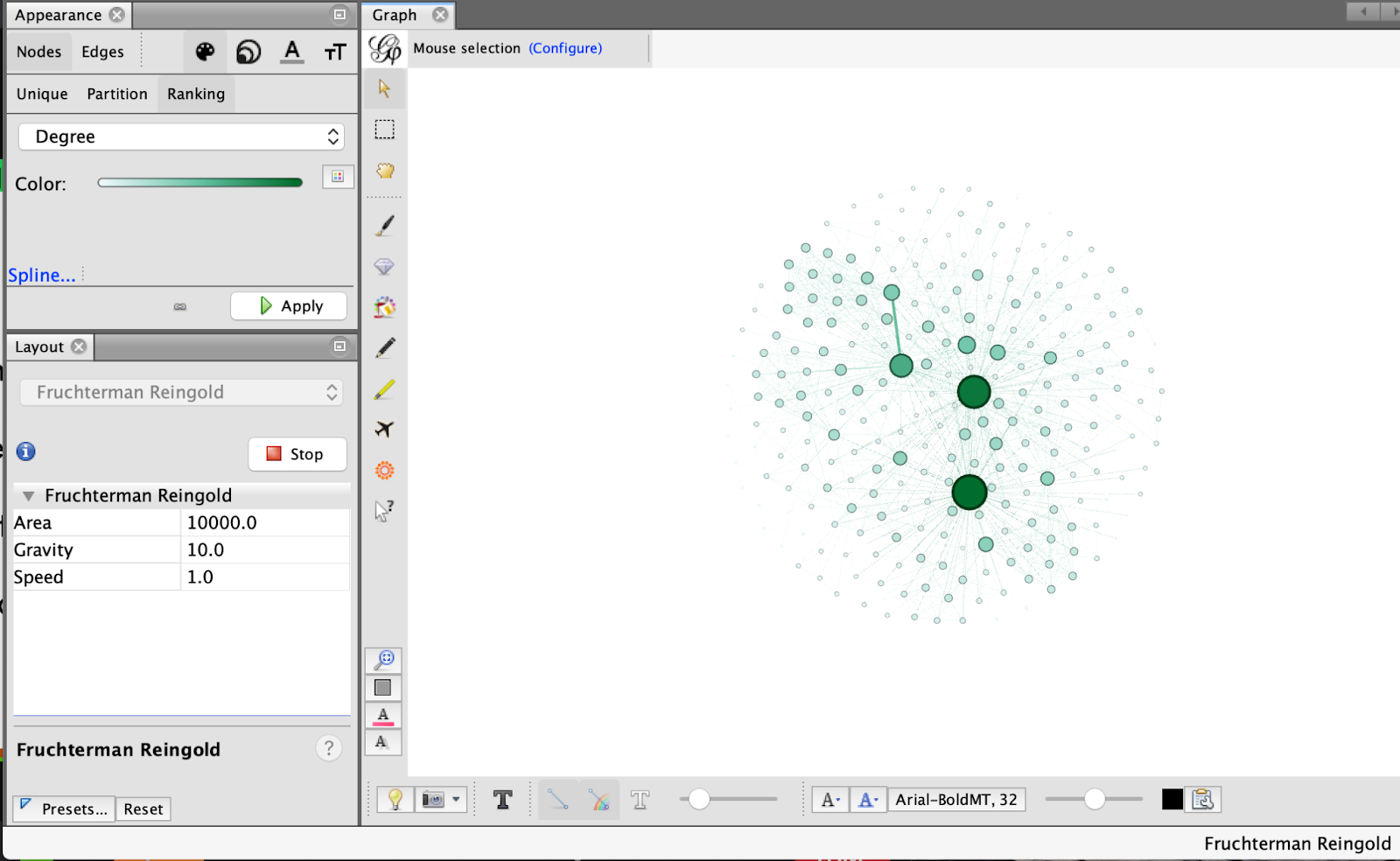
The next step I took was to use the Force Atlas 2 function in order to further define the layout of the network visualization. This function allowed more space for larger nodes (those with more connections) and dispersed less popular key terms. Two additional steps I took to make the layout more readable was to use the prevent overlap and scaling function.
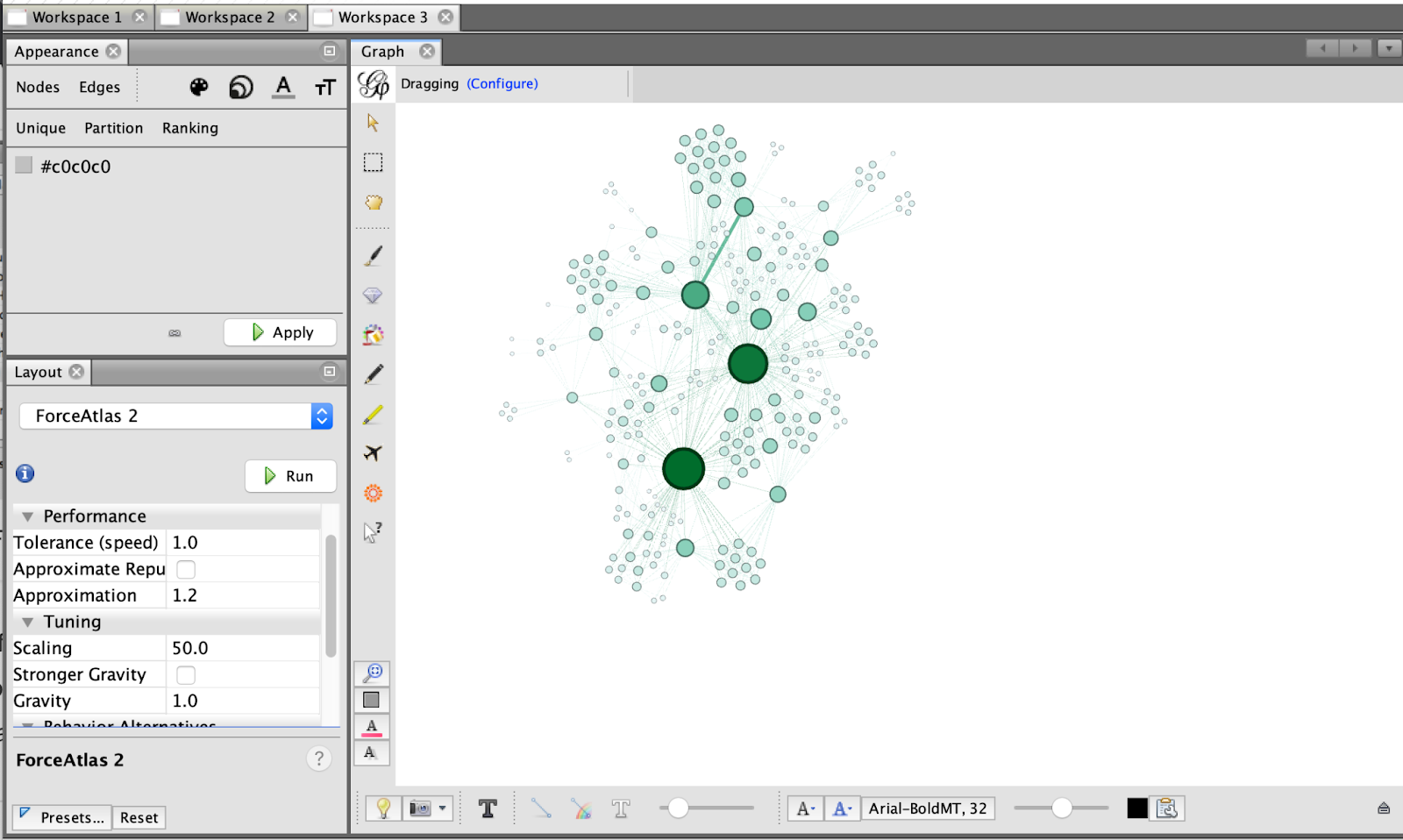
In order to understand which nodes meant which, I added node labels to the visualization and changed the coloring so that larger nodes were lighter and smaller were darker. Below, one can see what the network visualization looked like after taking these steps.
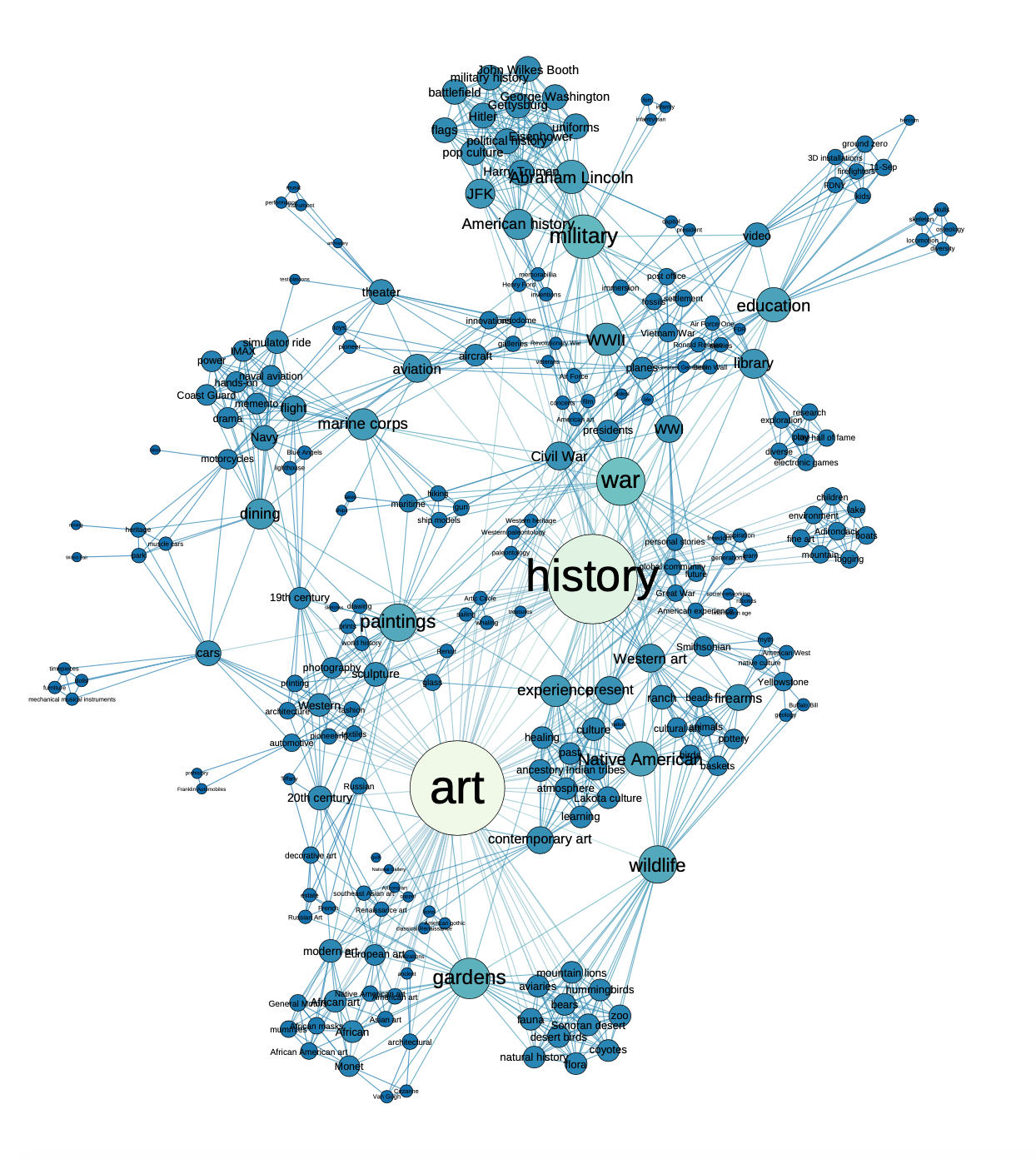
Once I was happy with this visualization, I started working to understand how these terms were related to one another. In order to understand what communities of nodes may exist (those nodes that were interconnected) I used Modularity. Modularity allowed me to see which communities of nodes existed and color these communities to see clear distinctions.
After this was done, I exported the data visualization using an SVG filetype and brought the visualization into Adobe Illustrator to better refine the visualization. I created a color palette which would create a clear separation between the communities and made the text readable to the viewer.
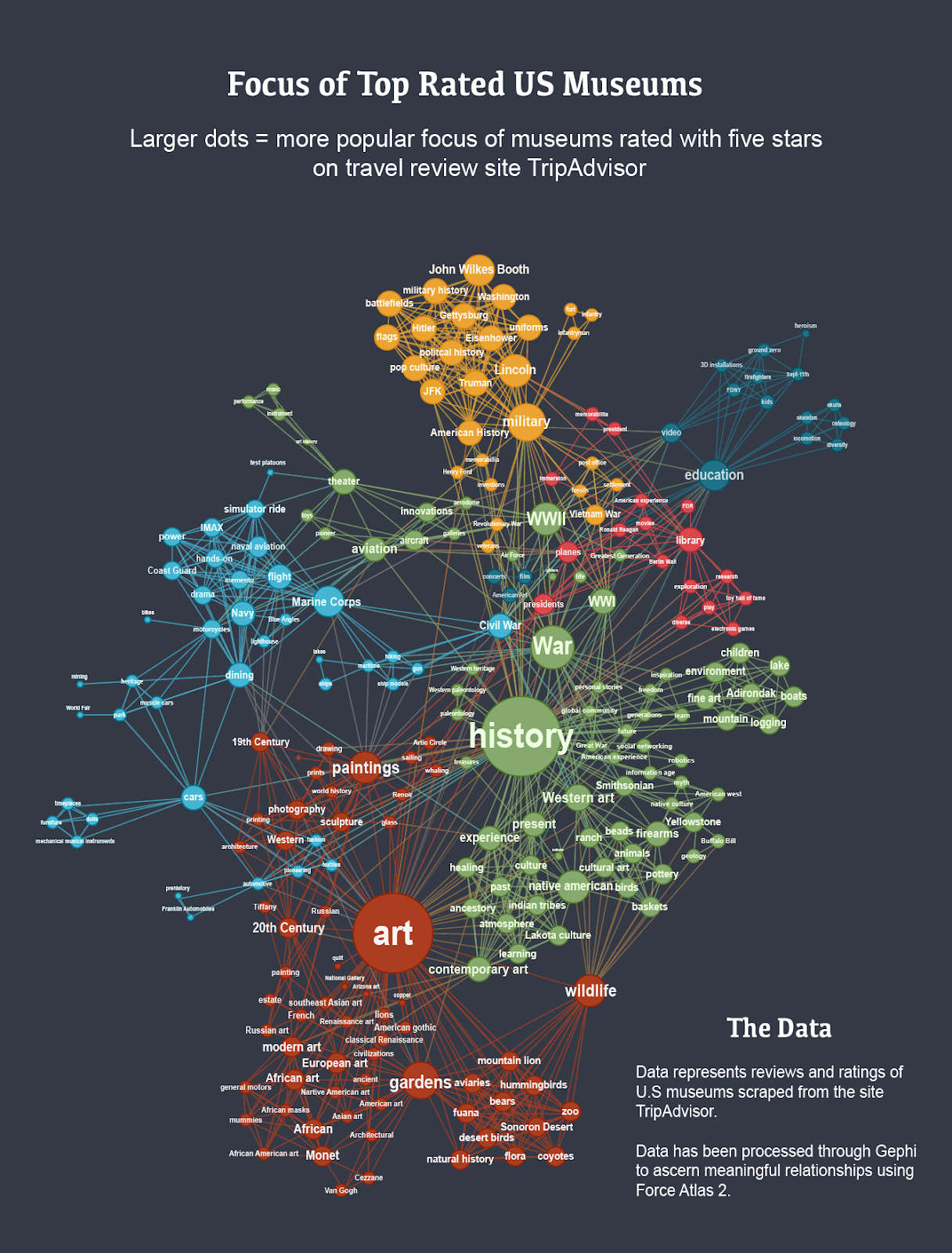
What I Learned
This process involved a lot of trial and error and through it I not only learned about Gephi, but additionally, learned new things about all the tools that went into its creation (Excel, OpenRefine, R, and Adobe Illustrator). In addition to the process, I learned more about the data as the network visualization helped me understand new insights about what makes museums popular. I learned that there is a relatively clear distinction between art and history museums, but both categories are interrelated to many other topics. For instance, there is a wide assortment of museums which feature artifacts related to wars and American museums favor distinct historical / artistic figures (Monet, Abraham Lincoln, Van Gogh, and John F. Kennedy). In terms of the museum’s interest in the rest of the world, there is a distinct fascination with Russia and Germany, two historical enemies. With a data analysis such as this, it is clear that many more insights could be garnered.