Alex Austin

Everyone’s a critic, or at least everyone has the opportunity to be a critic on the internet. Where once there existed a chasm between professionally published book reviews in print media and word of mouth recommendations, the internet has provided readers a platform to share their opinions about books with the world. One of the most popular sites on which readers rate and review books is Goodreads, who by their own description is “the world’s largest site for readers and book recommendations.”
Goodreads, by the very nature of its site, has been collecting data in the form of readers’ numeric and textual book reviews since its founding in 2007. A 2019 dataset of Goodreads data provides a glimpse into trends in the popularity of books and authors.
I chose to evaluate trends in reader reviews on Goodreads because like most people, I’m relatively familiar with popular book trends, so I would be able to spot if something seemed off in the data. If an obscure book outranked a very popular book in number of reviews, then I would know to check the dataset and see if there was an error. Since I’m new to working with datasets, this proved to be a good strategy. I cleaned the data in OpenRefine and imported it into Tableau to create visualizations.
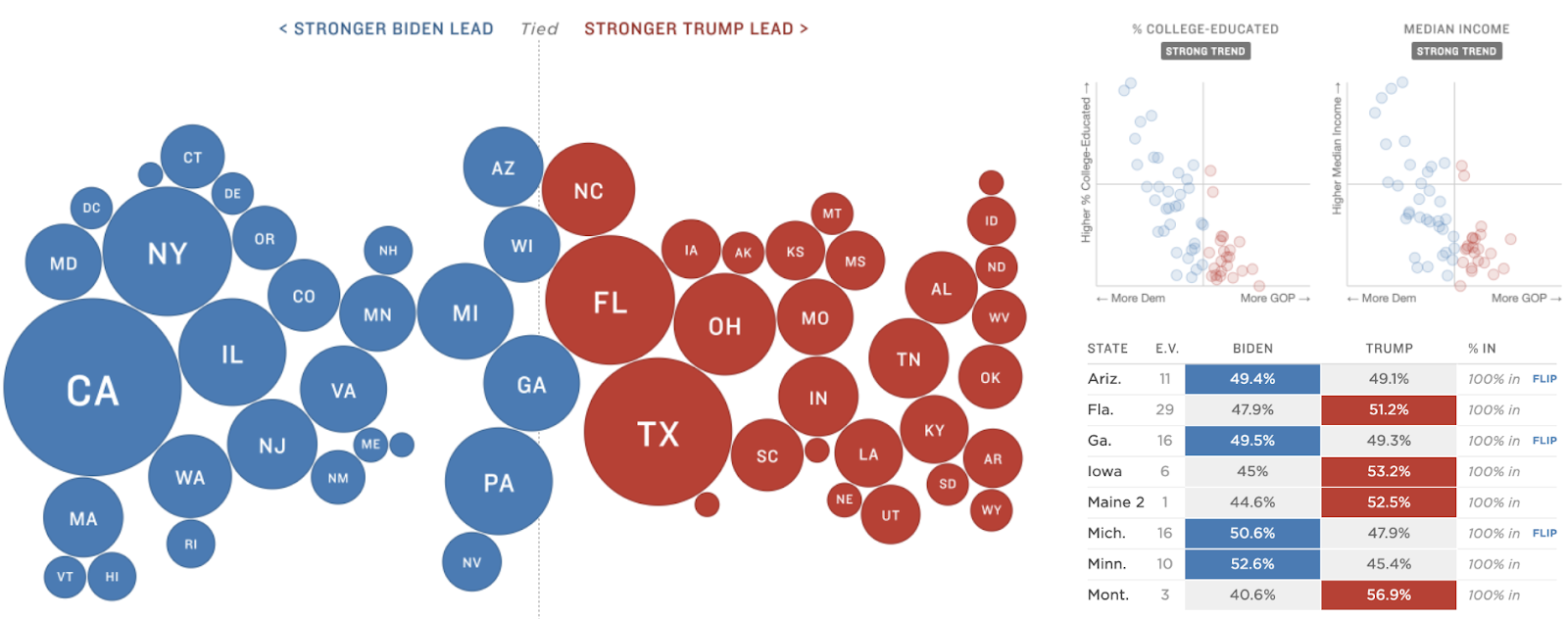
Around this time last year, I found myself mesmerized by a packed bubble map of live 2020 election results on NPR’s website. Its greatest draw was the critical information it was conveying, but the way that it presented the data was like nothing I had ever seen. Circles representing states were arranged on opposite sides of a midline, red on one side and blue on the other. The closer to the midline, the closer the race. Their size corresponded to the number of electoral college votes that each state had. The pack of colored bubbles that was the largest in area indicated who was in the lead. The election was a tight race, so I could watch as the circles would shift from one side towards the other, usually shifting from republican towards democrat as more mail-in ballots were counted.
I had this NPR visualization in mind when creating my first graph with the Goodreads data on Tableau. I created a packed bubble graph showing the most popular authors on Goodreads based on their ratings counts. J.K. Rowling came in first, followed by J.R.R. Tolkien and eight other recognizable popular authors. The numbers seemed to check out. Since J.K. Rowling was the most popular author, but the list was largely comprised of men, I wanted to break down the data by gender. The dataset didn’t include gender, so I manually assigned red to the authors I knew were women and brown to the authors I knew were men. You can see in the visualization that while only 2 of the top 10 authors are women, they account for roughly one third of the reviews. A pie chart might show the popularity breakdown by gender more clearly in terms of percentages, but then the legibility of the authors’ names and the distinctions between individual authors’ popularity may get lost.

One drawback to working with a dataset this large (17, 831 rows to be exact) is that it is difficult to evaluate and clean the data thoroughly before starting to play with it in the visualization software. I ran into some issues when making graphs with elements from different parts of the dataset. For instance, I tried making a graph showing the most popular books by review count, but Animal Farm kept showing up as the most popular with over 7 millions reviews, while the Harry Potter books trailed behind filling up most of the remaining top 10 slots. While Animal Farm is a classic, its popularity across demographic groups would not seems to outpace Harry Potter. I returned to the dataset and saw that Animal Farm was listed three times, with different authors, Orwell and two others, each time with the same number of reviews (2.1 mil). This error may have occurred when I manipulated the data in Open Refine, splitting authors apart when multiple were listed for a single book. Tableau added these reviews together and listed Animal Farm as the most popular book with 6.3 mil reviews. Fixing this error would have required reloading the data into OpenRefine and deleting the anomalous authors, but since OpenRefine doesn’t work on my Mac, this was not an option at the time. So, I pivoted to evaluate other parts of the dataset, and created three other graphs (How does page count relate to a book’s rating?, What’s the average length of a book by one of most popular authors?, and Average Ratings for Most Popular Authors by Book).


Another anomaly that occurs in the dataset is that it also only includes one book by the author Stephenie Meyer (the first Twilight book) when the remainder of the Twilight series has been in print for over a decade. Meyer’s popularity makes this gap in the data surprising. It can be observed in my graph titled “Average Ratings for Most Popular Authors by Book” as the lone data point above Meyer’s name. This made me question the comprehensiveness of the dataset in relation to the amount of data that Goodreads would have had on their site at the time of the dataset’s creation in 2019. I should note that the dataset was uploaded to the website where I found it in 2019, but that doesn’t necessarily mean that the dataset itself was created in 2019.

While I did gain some interesting insights into reader preferences and their behaviors when reviewing books online, I (more importantly) learned about the pitfalls of working with such large datasets. For my next lab, I think I should work with a smaller dataset, so that I can make sure that I’ve thoroughly cleaned it in OpenRefine before manipulating it in the visualization software.