
Using Gephi to Dive into a novel : David Copperfield by Charles Dickens
November 7, 2018 - All
Introduction
On this page, I used Gephi as a visualization tool to see the common words(adjectives and nouns) in the novel “David Copperfield” .
Inspiration
It brought delightment to me that things I learnt in Course 601: Foundation of Information connect to what I am doing in this project in Course 658: Data Visualization. Dr. Rabina just clarified that “Content Analysis” does not mean doing research on what message conveyed in a paper, it is rather a research on word count or paragraph as objects.
Material
After researching on this page of datasets, it turns that i found my interest. There are datasets of Web and internet, Social network, Biological networks, Infrastructure networks and Other works. I chose to investigate more on Word adjacencies, which is an “adjacency network of common adjectives and nouns in the novel David Copperfield by Charles Dickens. Please cite M.E.J.Newman, Phys.Rev.E 74, 036104 (2006)”
The source file is named “word_adjacencies.gml” . Since Gephi can open file with many forms including .gml, so I just need to open the program then import the file as a source.
Methods
The goal of Gephi is to “help data analysts to make hypothesis, intuitively discover patterns, isolate structure singularities or faults during date sourcing”. In order to make reasonable hypothesis, I reviewed wikipedia for a general idea of this novel. Then I have the following questions or hypothesis:
- The author Charles hold this novel as the”favorite child”, Can I see this through the network?
2. This novel contains descriptions based on Charles’ own childhood experience, can I see it?
Results
In the “Data Laboratory tab”, it can be seen that, there are 112 nodes with ID numbered from 0 to 111. As described in the name of the dataset, these 112 words are all common adjectives and nouns. Such as: agreeable, man, old, person, anything,short…..
Also in the Data Table in Data Laboratory of Gephi, it can be seen that value of each words are defined: adjective is defined as 0, noun is defined as 1. Besides, degree value is the sum of both In- Degree and Out- Degree.
The highest score of In- degree is 40, and the word is “little”; The highest score of Out- degree is 20, and the words are “same” and “good”; Overall, the top five highest score of Degree is 49: little, 33:old, 28:other,28:good and 21:same.
Interpretation
filter:Degree>5 A general map of common words can be seen. The word "little"has the highest degree of connection.



Filter:In-degree>5 Common Words: little, other, old, good
Filter:Out-degree>5 Common Words: Little, other, good, same
Compared with the last graph, the word “old” is missing, and the word “same” is here with higher out-degree. It can be estimated that less words adjacent with word”old” , such as “little old”, but more words adjacent with “old”, such as “old friend”,”old man”…
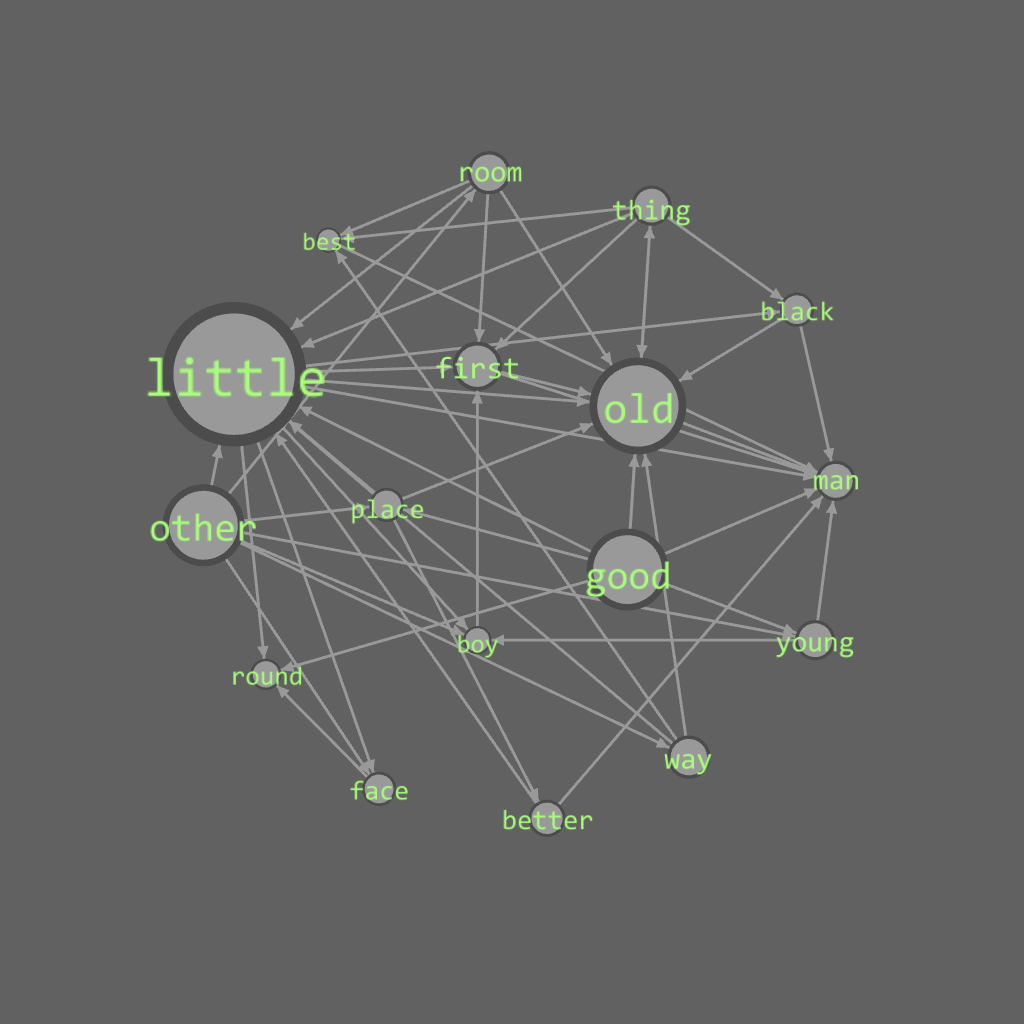
In-degree > 8
When focused on nodes with higher degree(in>8 and out>6). It is easier to research more on the direction of the connection.
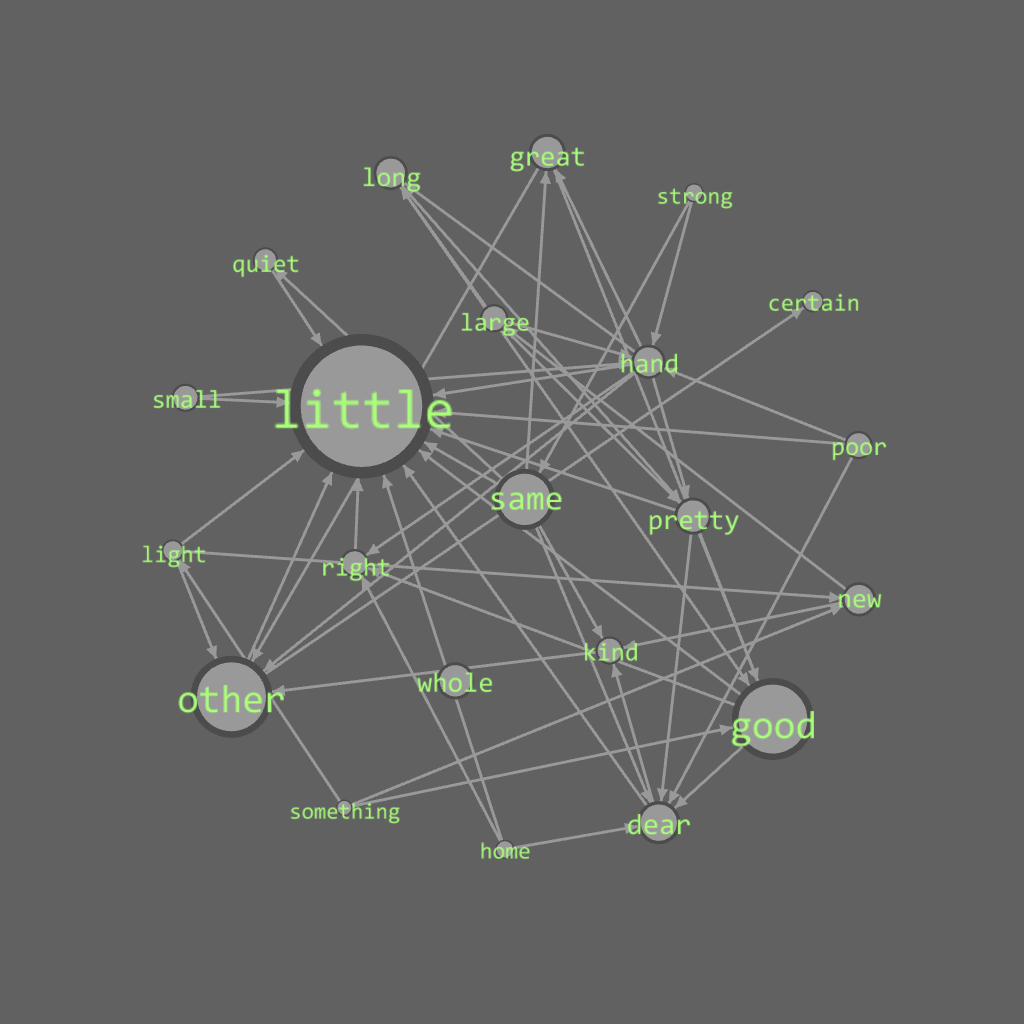
Out-degree >6
All these layout are based on “Fruchterman Reingold”, it turns the graph of netword into a round display, which is simple and direct to show network with lower modularity class(<1).
Out-degree >6

I adjusted color of nodes and size of nodes to show a better image of more information. I also switched the layout function to “ForceAtlas 2″
In this layout, nodes or words with the same degree of network are colored the same, as well as the size.
Below is a video/gif of flashing displays under function”ForceAtlas 2”.
Reflection
I wondered how did the source data generated these adjectives and nouns. I guess they need to have a collection or dictionary of all the adjectives and nouns to compare, then they generate lists of both adjectives and nouns used in this novel. They also need to set a standard of how many times of appearance can be considered “common”. Optionally, it might be necessary that to hold a balance between nouns and adjectives. Since this is a network analysis, if there are too many adjectives or too few adjectives, it may not be qualified for a network analysis and visualization.
Gephi is an open-source network analysis and visualization software. I used Windows to run this software and when I tried to open the working file (file named with .gephi ) I in the gephi software of Mac OS, it opened but with a blank layout. Thus, I switched back to Windows and went on with my process.
I am also interested in comparing the result with other works of Charles Dickens, maybe we can see the difference between “most loved child” and “the other children” . I am also investigating in grouping those nodes by degree, there is just not an end of playing with gephi.
The post Using Gephi to Dive into a novel : David Copperfield by Charles Dickens appeared first on Information Visualization.