Changing demographics due to the rising populations in Brooklyn have had an impact on businesses, in particular, restaurants. The type and number of restaurants in an area can be a good indicator of lifestyle and income of its residents. After recently moving back to Brooklyn, I have noticed an increase and change of cuisine of restaurants just in the past year I have been here. I felt that exploring types and number would provide an interesting viewpoint on the neighborhoods of the borough.
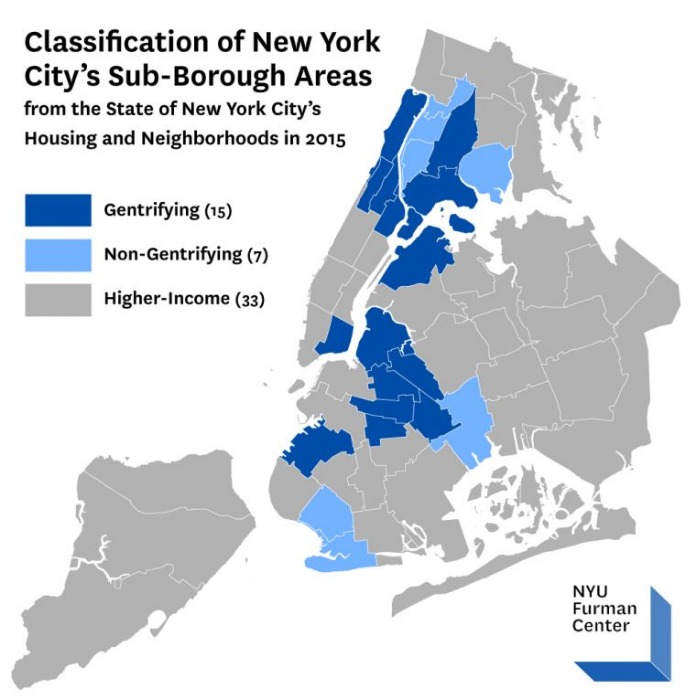
Source: NYU Furman Center’s 15th Annual State of New York City’s Housing and Neighborhoods in 2015
Process
Data Collection
Searching through NYC Open Data for information on restaurants, I did not find any list of all active restaurants. Instead, I discovered the DOHMH New York City Restaurant Inspection Results dataset and was able to pull information I could use. Because any restaurant that is active or opening would need to be inspected, I reasoned that this would be a good source. I downloaded the dataset and then used OpenRefine to only include restaurants in Brooklyn. The data is not ideal in that some locations are listed more than once, so the data is more of an indicator of restaurant activity than the actual number of businesses.
NYC Open Data (https://opendata.cityofnewyork.us/data/)
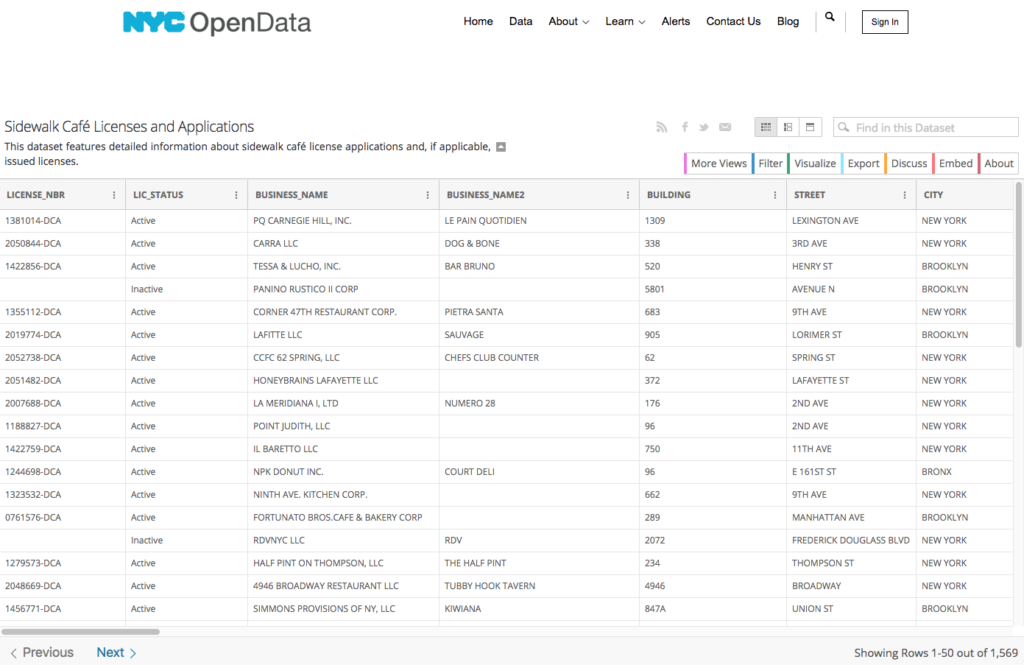
I also found a dataset with all the restaurants in the city that had sidewalk seating. This dataset including square footage and the number of seats along with the location. These were the three values I was most interested in. I refined the data to only show active licenses in Brooklyn since applications and expired ones may not be in use. I felt this data provided additional insight into the connection between restaurants and demographics. Not only were most places in a waterfront location as you would expect, but also in higher income and gentrified areas such as Williamsburg and Greenpoint.
DOHMH NYC Restaurant Inspection Results Dataset
Data Visualization
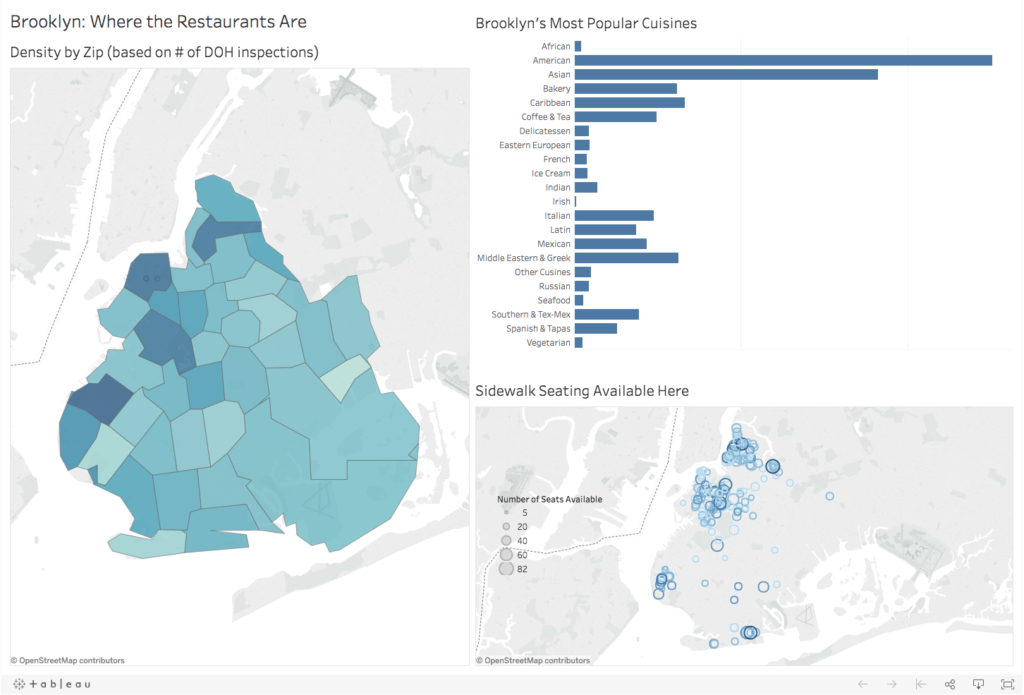
Using the first dataset with the health inspections, I was able to create a map that displayed density of activity by zip code. I also created a bar graph that displayed the popularity of cuisines from this same dataset. Since the type of cuisine was random and sometimes granular, I grouped several values together in Tableau. For example, under the label “Latin”, I have included Brazilian and Peruvian restaurants. Because both of these charts are generated by the same data, clicking on one zip code in the density map will update the cuisines bar chart, illustrating which ones are more popular in that zip code.
The sidewalk seating map shows the location and indicates the number of seats with the marker size. The darker the color the greater the square footage. Because the circle markers are outlines, you can easily see the density in certain areas. Being generated by a different dataset, this map does not react to changes in the other two.
Source: NYC Open Data. Visualizations based on the DOHMH NYC Restaurant Inspection Results and Sidewalk Café Licenses datasets from the NYC Open Data site.
A quick view of the dashboard gives a clear idea of where the most restaurants are located along with additional information on popular cuisines and sidewalk seating. It features the map of inspection activity by zip code along with a bar graph of the cuisines to the right. Additionally, there is a sidewalk seating map to the right below the bar graph. I felt the sidewalk data was a supporting element in relation to the activity. I chose not to include my graph on the number of inspections increasing over time since my other charts were not historic. Of course, the overall number of restaurant inspections increasing makes perfect sense considering the rise in population, incomes, and gentrification.
Future Considerations
I would have liked to show a greater relationship between the changes in businesses and gentrification. This could have been done between datasets that include zip codes. Using the zip as the link between tables, many more relationships could be discovered. Many datasets use districts rather than zip codes which makes creating connections between them more challenging.