Revisiting the Paston Letters Network
April 19, 2018 - All
The Pastons were a gentry family that lived in the village of Paston in Norfolk, England, during the fifteenth century. Their letter and document collection, which dates between 1422 and 1509, provides valuable evidence of land struggles, wealth acquisition, love interests, and family crises that the Pastons encountered during this time (The British Library Board, 2015). This visualization is a reimagining of a network I created for a previous course at Pratt on the Paston family letters, which highlighted the types of relationships between the Paston letter writers and recipients without formatting the layout or considering modularity. The new network presented here incorporates these aspects with the relationships types to reveal the overarching groups within the collection.
Example Visualizations

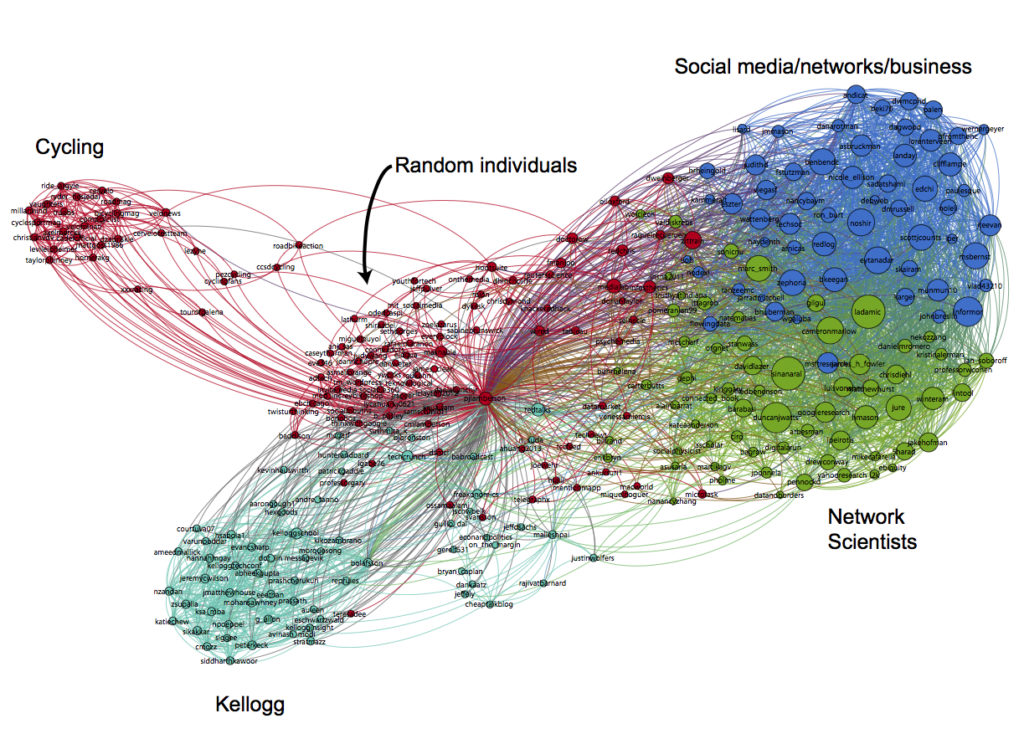
I chose the first example visualization (Figure 2) for two main reasons, the first being its color-coded clustering. Colorization is a pre-attentive attribute that is among the easiest for the human eye to detect (Few, 2009). Its usage here makes identification of the different clusters fairly straightforward, although the red and the green could cause some confusion for those who are colorblind. The second reason I chose this example is because of its named clusters. I had hoped to identify the different groups in my own graph and perhaps create a hypergraph based off of those classifications. Although I did not ultimately do this, I like the idea of identifying how these individuals are clustered. There are also two aspects of this example that I think make it difficult to interpret. Each node is identified in the final product, indicating that each person in the network is worth knowing. However, these labels are too small to read and it is impossible to tell who is connected to whom. In the end, they just contribute to chartjunk (Tufte, 2001). For my network, I have tried to learn from this lesson by making clearer labels that reveal the relationships within the graph.
I chose my second example (Figure 3) because of its hues; the green, blue, purple, and orange are typically simple to identify, even for those who are colorblind. With my own network, I varied the shades slightly between these colors but still focused on those particular colors. The only concern regarding color that I have with this example, though, is that the different shades of greens may not be as quickly identifiable as separate colors. Although the different positions of the nodes indicate that they are distinct clusters, I did not notice the contrast at first glance.
In addition to the colors, I liked the look of the edges in this example. I prefer the clean impression that the straight edges give the visualization and wanted to mimic that in my own. I also thought the weighted edges, or the changing thickness based on some numerical aspect of the relationships, added depth to the visualization and made the strength of certain relationships clear. This style takes advantage of the size pre-attentive attribute, which emphasizes the significance of larger edges (Few, 2009).

The final example visualization (Figure 4) I selected is also colored by cluster, with distinct hues and shades for each one. Again, the red and the green together would be difficult for a colorblind person to identify, especially because they are side-by-side. In addition to the color, the distinct positioning of each cluster, another pre-attentive attribute, is helpful in distinguishing one from another (Few, 2009). Finally, the different sizes of each node imply varying amounts of significance for each one, which I wanted to use in my own visualization.
Materials
The data set that I used for this visualization is one that I compiled for the Program for Cultural Heritage course (LIS 664) at Pratt Institute. Using the programming language Python, I scraped data in the digital edition of Norman Davies’ Paston Letters and Papers of the Fifteenth Century, pulling information about the sender of each letter and document as well as its recipient. After converting the JSON file I had created with the scrape to a CSV, I cleaned it in OpenRefine. This step involved normalizing spelling, removing drafts that would have created duplicates, and taking out any non-letter documents. I then manually added the relationship types to each entry and exported it as a new CSV file.
The software that I used to create this network visualization was Gephi. Gephi is an open-source networking software available for free online. Users can employ different layouts, statistics, and styling techniques to display and examine their network data. They can export these networks in static SVG, PDF, and PNG formats, or as interactive networks using the sigma.js plugin. Gephi also has a robust support community, including a Facebook group, Wiki, and free datasets.
Methods
I created this visualization in three overall steps. First was breaking the nodes down into modularity classes, or clustering them. Modularity classes are developed using an algorithm that detects the groupings based on the connections, the weight of those connections, and a selected resolution. The resolution used in the algorithm can determine how many modularity classes are detected in the network. Higher resolutions cause fewer classes, and lower resolutions generate more. For this visualization, I used a resolution of 0.15, which resulted in four modularity classes.
The second major step was the use of the Yifan Hu Proportional layout to reorganize the structure of my visualization. The original Yifan Hu layout uses an attraction-repulsion model and restricts force calculation to the neighborhood. It also has an adaptive cooling scheme that allows the algorithm to stop running automatically (Hu, 2005). The proportional version of this layout modifies the original by using a proportional displacement scheme. I used this layout for my visualization because it made the groups within the network distinctly stand out against each other, while emphasizing the core family members who held the network together.
The final step was styling the visualization. I weighted my edges based on the number of letters sent from one individual to another, using the pre-attentive attribute of size to draw attention to the significance of each relationship. For example, John Paston III sent Richard Croft one letter, therefore the edge is weighted as one. Margery Paston sent John Paston III three letters, so this edge is weighted at three. These weights were then rescaled so as to not overpower the visualization and make it look messy. Similarly, I reduced the arrow size for the directed relationships to 2 so that they did not take up the entire network. I also changed the size of the nodes to match the relative output of each writer.
Additionally, I colored each edge by the type of relationship between writer and recipient, which, when combined with the varying size of the edges, could indicate which types of relationships were most frequently corresponding. I also colored each node according to modularity class to more obviously cluster them and reduced the borders since they were largely unnecessary for this visualization. Finally, I showed the labels on the nodes so that users could see who was writing to whom. I used the Didot 12-point font in black, which made the labels easy to read on this visualization.
Results & Discussion
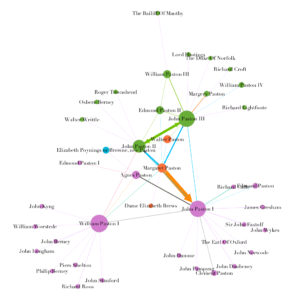
The final result of this lab (Figure 5) reveals the communities within the Paston letters collection. In particular, one can see where the core family sits amid the different generations of business contacts. It is a significant improvement on my previous project, which did not take into account modularity classes or the clean layout. The groups I wanted to reveal before are now much more distinct.
In terms of working with Gephi, it allowed me to easily cluster the social circles within the Paston Letters Network, including familial and professional relationships. Additionally, I was able to show the relationships distinctly through changing the color while also showing the modularity class through the color of the nodes. The balance of these two ideas were fairly simple to implement with this software. Further, I was able to select a layout that made the neighborhoods within these groups more visible.
Gephi did, however, have some drawbacks. In particular, it was occasionally difficult to use because of how slow the software could be and how often it crashes. I had to switch to my personal laptop from a school computer because Gephi could not function properly on the latter. The language Gephi used in general was also somewhat unclear. While it may be common vocabulary for network scholars, it could be more user-friendly and jargon free.
I also want to point out a particular limitation in my data. Because these are medieval letters, they run the risk of being incomplete. Not all letters may have been kept initially, and some may have been lost through time or thanks to decay. Therefore, this visualization represents the network that has been handed down to us. It is the best we can create given this caveat, but, as with all history, it may not represent the whole story.
Future Directions
While this lab is an implementation of future directions of a previous project, I still have several ideas in mind where I would like to go with it. First of all, I would like to make this network interactive. The sigma.js plugin should be able to export an interactive version, but I was unable to make it work. Additionally, I would be interested in somehow making this an animated network. I do not know if Gephi would be able to create this at all, but an animation showing the letters moving and the network evolving could provide valuable insight into how these relationships developed over time. In addition to these features, I would like to learn more about modularity and tweak my resolution to get the classes to be more revealing. While I am happy with the results I have, I think these communities could be broken down a little further. Finally, I would be interested in creating a hypergraph of the clusters created by the modularity classes. I did not have time to complete that in our lab, but I think they could roughly define the different sections of the network.
References
The British Library Board. (2015, April 26). The Paston letters go live. The British Library – Medieval Library Blog. Retrieved from http://blogs.bl.uk/digitisedmanuscripts/2015/04/the-paston-letters-go-live.html#
Few, S. (2009). Now you see it: Simple visualization techniques for quantitative analysis. Oakland, CA: Analytics Press.
Hu, Y. (2005). Efficient and high quality force-directed graph drawing. The Mathematica Journal, 10, 37-71. Retrieved from http://yifanhu.net/PUB/graph_draw_small.pdf
Tufte, E. (2001). The visual display of quantitative information (2nd ed.). Cheshire, CT: Graphics Press.
The post Revisiting the Paston Letters Network appeared first on Information Visualization.